Comment faire travailler un agent IA sur un codebase legacy massif sans perdre le contexte ni l'argent
Ça vous parle ? Vous demandez à Claude ou ChatGPT de comprendre la logique d'un vieux projet, et il commence à « halluciner » ou brûle tout son quota de tokens en essayant de lire des centaines de fichiers avec un simple grep. Même les agents modernes comme Claude Code se comportent souvent comme des chatons aveugles quand il s'agit de saisir les connexions profondes entre services ou les chaînes d'appels complexes.
L'autre jour, je suis tombé sur le dépôt codebase-emory-mcp. C'est un serveur MCP (Model Context Protocol) qui transforme votre code en un graphe de connaissances structuré. Au lieu de nourrir le réseau de neurones avec du texte brut, l'outil construit une carte des fonctions, classes et dépendances que l'IA peut comprendre en un demi-mot.
Quel est le problème avec la recherche classique
Quand un agent IA essaie de comprendre votre code, il procède généralement par force brute. Il lance des recherches de chaînes de caractères, ouvre les fichiers un par un, et essaie de tout garder en tête. Le problème, c'est que la fenêtre de contexte n'est pas infinie. Si le projet est volumineux, l'agent oublie rapidement le début de la chaîne d'appels ou commence à confondre des méthodes similaires dans différents modules.
Les développeurs de DeusData affirment des chiffres impressionnants : utiliser leur graphe réduit la consommation de tokens de 120 fois. Là où un agent classique doit traiter 400 000 tokens, cet outil n'en nécessite que trois à quatre mille. Ce n'est pas seulement une question d'économies sur les appels API—c'est avant tout une question de précision des réponses.
Ce que ce moteur peut faire
Le projet est écrit en C « pur » et utilise SQLite pour le stockage. Ça donne une vitesse folle. L'indexation du noyau Linux (ça représente 28 millions de lignes de code) ne prend que trois minutes. Un projet Django ou React classique est « avalé » en quelques secondes.
Voici quelques fonctionnalités qui ont retenu mon attention :
- Compréhension de l'architecture. L'outil ne voit pas que du texte, mais la structure. Il distingue les points de terminaison API, comprend quelle fonction appelle quelle autre, et trouve même le code « mort » que personne n'utilise.
- Support de 66 langages. Grâce à tree-sitter, le moteur comprend presque tout—du Python et TypeScript au Rust et COBOL. De plus, pour C, C++ et Go, il peut inférer les types à la manière LSP.
- Visualisation. Il est livré avec un visualiseur de graphe 3D (optionnel). Vous pouvez littéralement faire tourner votre projet dans le navigateur à
localhost:9749et voir comment les modules sont connectés. - Intégration avec les agents. Avec une seule commande
install, l'utilitaire se configure pour Claude Code, Zed, Aider et une douzaine d'autres outils populaires.
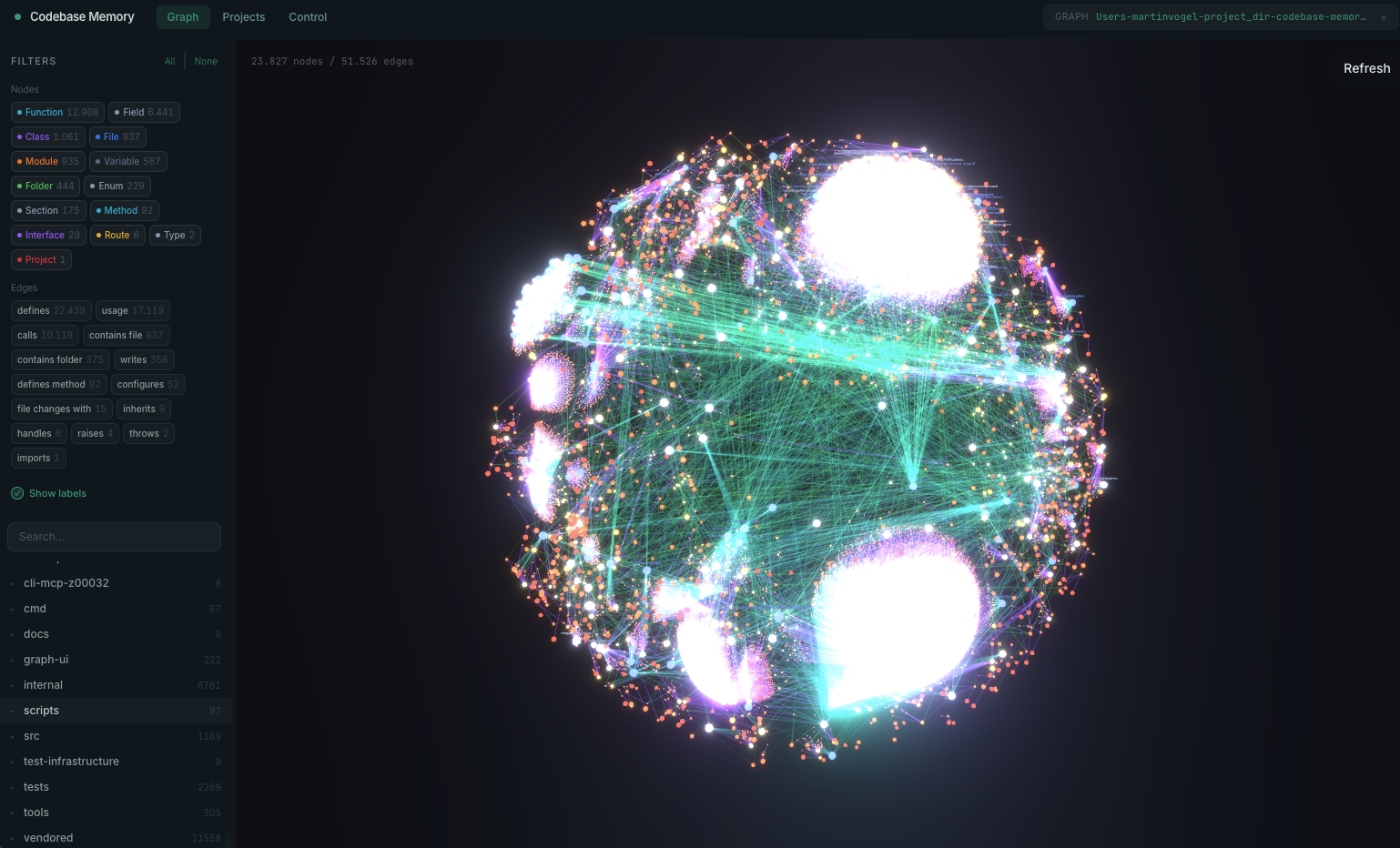
Ce fameux graphe 3D que vous pouvez faire tourner dans le navigateur
Comment ça fonctionne sous le capot
Curieusement, les auteurs ont décidé de ne pas intégrer leur propre LLM pour traduire les requêtes en commandes de base de données. Ils ont raisonné intelligemment : puisque vous parlez déjà à un agent intelligent (comme Claude 3.5 Sonnet), autant le laisser gérer la traduction.
Vous demandez : « Qui appelle la méthode ProcessOrder ? ». L'agent comprend l'intention et appelle l'outil trace_call_path. Le moteur traverse le graphe en millisecondes et renvoie une réponse structurée. Résultat, l'IA voit une chaîne claire au lieu d'essayer de la deviner à partir d'indices indirects.
SQLite en mode WAL est utilisé pour le stockage, et les données sont compressées avec l'algorithme LZ4. Cela permet de garder l'index même de très grands projets directement en mémoire pendant l'exécution sans stresser le disque.
Bénéfices pratiques pour les développeurs
Le cas d'utilisation le plus évident est l'onboarding sur un nouveau projet ou la refactorisation d'un ancien. Au lieu de construire manuellement des diagrammes dans votre tête, vous donnez à l'agent accès à codebase-memory-mcp.
Par exemple, vous pouvez demander : « Trouve tous les endpoints qui acceptent UserID mais ne vérifient pas les droits d'accès ». L'outil trouvera les connexions entre les routes HTTP et les méthodes de validation que la recherche textuelle classique raterait.
Une autre fonctionnalité intéressante est detect_changes. Il analyse votre diff git actuel et montre le « rayon d'impact » : quelles fonctions et quels modules vos modifications vont affecter. C'est une excellente assurance avant de commiter.
Comment l'essayer
L'installation est simple comme bonjour—pas de Docker ni de dépendances supplémentaires. Pour macOS et Linux, une seule commande terminal :
curl -fsSL https://raw.githubusercontent.com/DeusData/codebase-memory-mcp/main/install.sh | bash
Si vous voulez la visualisation directement, ajoutez le flag --ui. Après l'installation, redémarrez simplement votre agent IA et dites-lui : « Indexe ce projet ».
Est-ce que ça vaut le coup
Le projet semble très prometteur. Ce que j'aime particulièrement, c'est que ce n'est pas un autre service cloud, mais un utilitaire local. Tout votre code reste sur votre machine—aucune donnée n'est envoyée vers des serveurs externes pour l'indexation.
Bien sûr, il y a des nuances. La qualité de l'analyse pour certains langages comme Haskell est encore inférieure à celle pour Python ou Go, langages mainstream. Mais la liste des technologies supportées et la vitesse de traitement compensent largement ces imperfections.
Si vous utilisez activement l'IA dans votre développement quotidien et que vous sentez qu'elle commence à « caler » sur des tâches complexes, cet outil pourrait être ce maillon manquant. En tout cas, la possibilité de voir votre projet sous forme de graphe 3D vaut certainement les dix minutes d'installation.
Projets similaires