SQLiteの圧縮をスムーズに:sqlite-zstdの魔法
1,681 スター
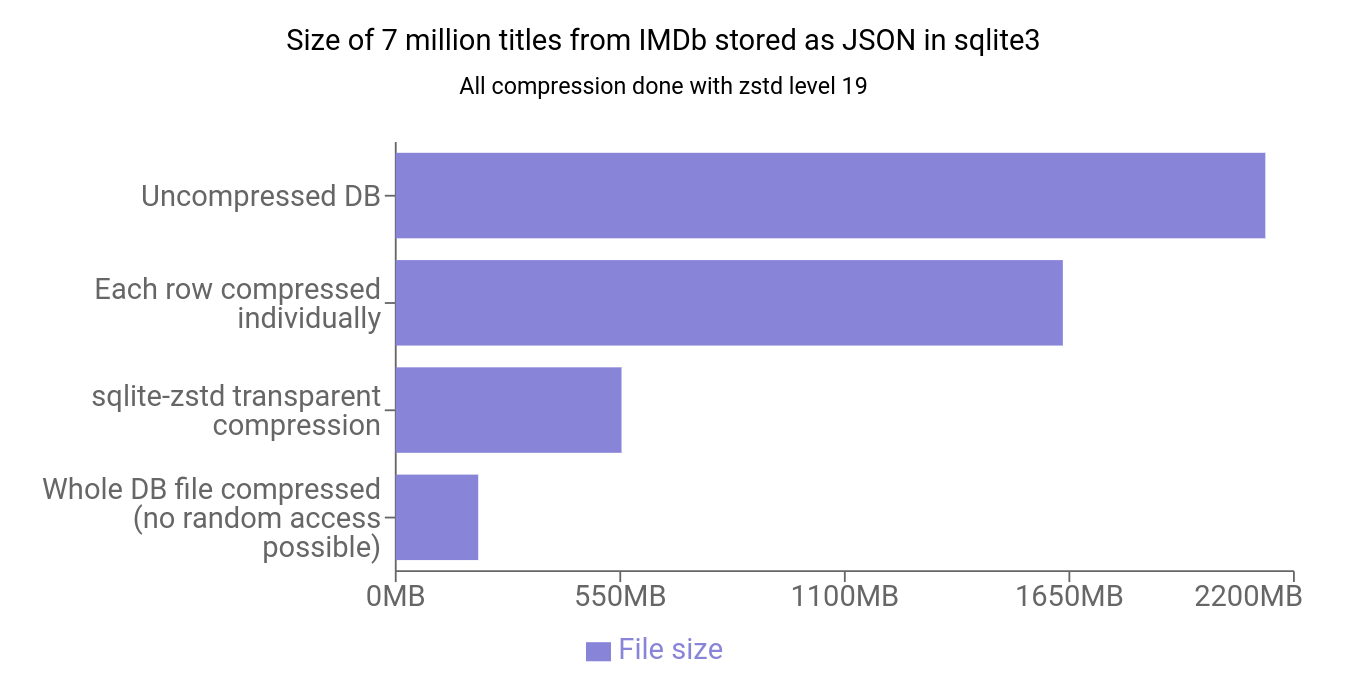
このような経験はありませんか?SQLiteデータベースを持つアプリケーションがギガバイト単位の大きさに膨れ上がり、バックアップに時間がかかり、I/O操作がすべてを低速化させている。sqlite-zstd拡張は、ランダムデータアクセスを維持しながら行レベル圧縮を提供するエレガントなソリューションです。
このツールとは?
sqlite-zstdは、Zstandard(zstd)アルゴリズムを使用して透過的な行レベルデータ圧縮を追加するRustで書かれたSQLite拡張です。データベース全体を一度に圧縮するのとは異なり、このアプローチは以下のことができます:
- スペースの最大80%を節約(作者によると)
- データへのランダムアクセスを維持
- パフォーマンスへの影響を最小限に抑制
誰が使うべきか?
このプロジェクトは以下のユーザーに特に便利です:
- 1メガバイトたりとも無駄にできないモバイル開発者
- 大きなログや履歴データを持つサービス
- SQLiteでJSON/テキストデータを扱うアプリケーション
- ストレージが限られた組み込みシステム開発者
主な機能
1. 透過的な圧縮
SELECT zstd_enable_transparent('{"table": "logs", "column": "data", "compression_level": 19}')
これ以降、logsテーブルでのすべての操作が、data列のデータを自動的に圧縮/解凍します。コードは変更に気づきません!
2. 増分メンテナンス
SELECT zstd_incremental_maintenance(60, 0.5);
この関数を使用すると、データベースを長時間ロックせずにデータを徐々に圧縮できます。どのくらいの時間作業し、他の操作にどのくらいの時間を残すかを指定できます。
3. 辞書サポート
プロジェクトはより良い圧縮用の辞書を作成して使用できます:
SELECT zstd_train_dict(data, 100000, 1000) FROM logs
これは構造化データ(例:重复するキーを持つJSON)で特に効果的です。
内部での動作仕組み
- 圧縮可能なテーブルごとに隠しシャドウテーブルが作成されます
- 元のテーブルはデータを透過的に圧縮/解凍するビューになります
- INSERT/UPDATE時、データは自動的に圧縮されます
- SELECT時、データは解凍されます
実践的なユースケース
例1:アプリケーションログ
# Python пример с Datasette
import sqlite3
import sqlite_zstd
conn = sqlite3.connect('logs.db')
sqlite_zstd.load(conn)
# Включаем сжатие для колонки с логами
conn.execute("""
SELECT zstd_enable_transparent('{"table": "logs", "column": "message"}')
""")
例2:JSON APIレスポンスの保存
// Rust пример
let conn: rusqlite::Connection;
sqlite_zstd::load(&conn)?;
conn.execute(
"SELECT zstd_enable_transparent('{\"table\": \"cache\", \"column\": \"json\"}')',
[],
)?;
制限事項
- まだ本番対応ではない(作者の意見)
- 圧縮データベースのATTACHをサポートしていない
- DDL操作のサポートが限定的
- TEXT/BLOB列のみ対応
sqlite-zstdは:
✅ SQLiteデータベースサイズを削減するシンプルなソリューション
✅ 既存のコードへの最小限の変更
✅ 圧縮プロセス柔軟な制御
試してみるべき人:
- SQLiteデータベースが不当なサイズに達している人
- 多くのテキスト/バイナリデータを保存する必要がある人
- 実験 готовностьがある人(ただしバックアップを忘れずに!)
このプロジェクトは積極的に開発中で、GitHubで既に約1.6kのスターを獲得しています。スペースを節約したいですか?sqlite-zstdを統合するのに最適なタイミングは今です!
関連プロジェクト