Nightingale - 当告警成为一门艺术
问题:为什么我们讨厌告警?
眼熟吗?凌晨3点你被一条服务器崩溃的短信叫醒,慌慌张张地连接VPN,结果发现——虚惊一场。而到了早上一切风平浪静时,关于数据库过载的重要警告却被淹没在数百条“部署成功”的消息中。
这些正是 Nightingale 要解决的痛点——一个开源监控系统,告警不仅仅是存在,而是被提升为一门艺术。
什么是 Nightingale?

Nightingale 最初由滴滴(中国的 Uber)开发,后来开源,自称为“告警专家”。如果说 Grafana 是可视化之王,那么 Nightingale 就是通知领域的 virtuoso( virtuoso 意为技艺精湛者)。
该项目的主要亮点——不仅仅是收集指标,而是智能处理告警:
- 智能告警降噪
- 关键事件升级
- 20+ 内置通知方式(从 Slack 到 SMS)
- 自愈能力(自动修复)
尝试 Nightingale 的五大理由
1. 不会无缘无故叫醒你的“智能”告警
Nightingale 可以:
- 将相关事件分组(例如,一个集群中 100 个 Pod 崩溃)
- 过滤误报
- 自动提升“陈旧”告警的优先级
2. 灵活的通知场景
你想要:
- 首次告警发送到 Slack
- 重复告警以 SMS 发送给工程师
- 严重故障直接打电话给你?
Nightingale 通过直观的“通知规则”处理这些需求,无需编写脚本。
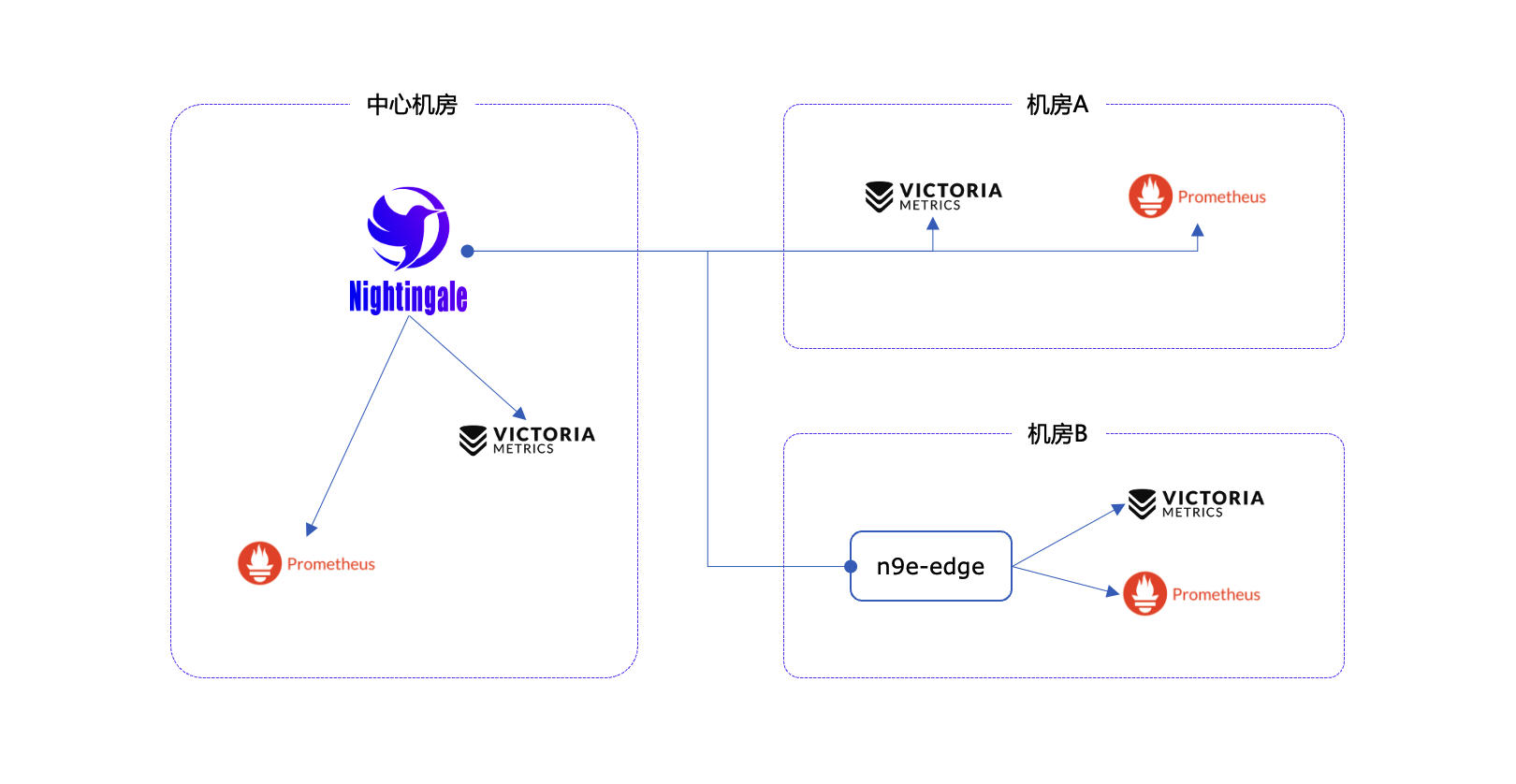
3. 适用于分布式基础设施
对于网络不稳定的边缘位置,它提供边缘模式——一种本地告警引擎,即使与中心的连接中断也能继续工作。
4. 开箱即用的仪表盘和规则
项目包含预装的:
- 流行数据库和中间件的仪表盘
- 告警规则模板(可从 Prometheus 导入)
- 指标说明(无需猜测 的含义)
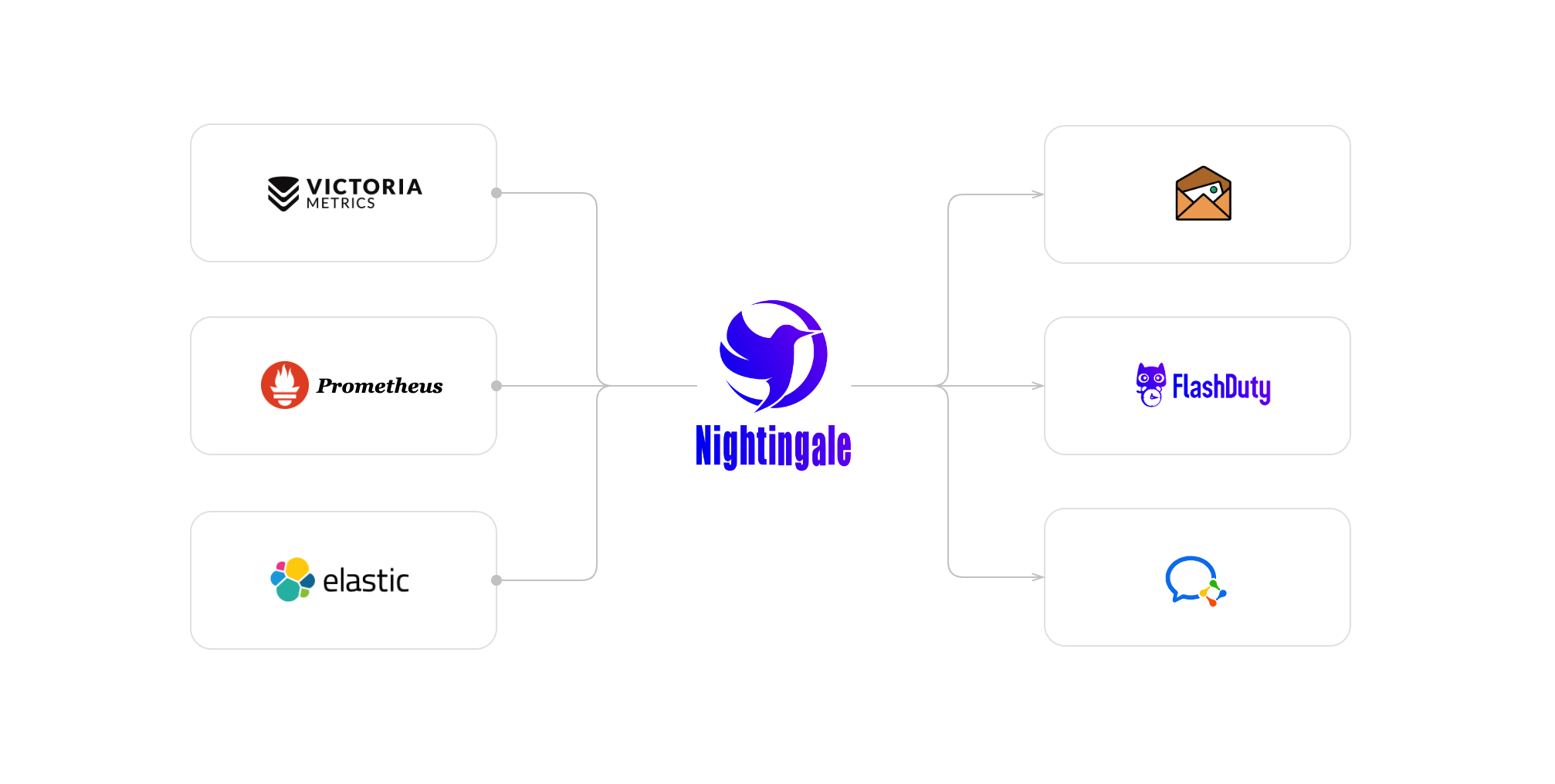
5. 与万物集成
- 数据源:Prometheus、VictoriaMetrics、ElasticSearch、Loki、MySQL
- 协议:Prometheus Remote Write、OpenTSDB、Datadog
- 代理:推荐使用 Categraf,但也支持其他代理
底层原理是什么?
从架构上看,Nightingale 由以下部分组成:
- 告警核心 — 评估规则,管理事件生命周期
- 连接器 — 适配各种指标存储系统
- 通知引擎 — 根据定义的规则路由告警
- API 用于与外部系统集成
主要使用 Go 语言编写,即使在高负载下也能保证良好的性能。
谁会觉得它特别有用?
- 拥有分布式基础设施的团队 — 边缘模式确实能派上大用场
- 受够了“告警轰炸”的人 — 这个系统真的知道如何过滤噪音
- 有合规要求的企业 — 灵活的角色系统和业务分组
- 已经在使用 Prometheus 的任何人 — 集成几乎是无缝的
局限性
Nightingale 不是银弹。对于复杂场景,例如:
- 完整的事件管理
- 值班轮换
开发者坦诚建议使用专业的解决方案,如 PagerDuty。
如何开始使用?
对于测试,可以使用 Docker 镜像:
docker pull flashcatcloud/nightingale
结论:值得一试吗?
如果你有:
-
10 台服务器
-
每天 5 条告警
- 上个月至少有一次夜间误报
——那绝对值得一试。Nightingale 会拯救你的神经和团队的神经。
对于较小的项目,可能继续使用 Prometheus Alertmanager + Grafana 的组合会更简单。但当告警成为痛点时,这是我们见过的最好的开源选择。
附注:该项目正在积极开发中——在过去一年中,新增了对新存储系统的支持,并改进了边缘设备的工作。GitHub stars 正在快速增长:

试试看吧——也许这正是你一直在寻找的工具。
相关项目