Nightingale - When Alerting Becomes an Art
The Problem: Why Do We Hate Alerting?
Sound familiar? At 3 AM you're woken up by an SMS about a server crash, you panic-connect to the VPN, and it turns out — false alarm. In the morning, when everything is calm, an important warning about database overload gets buried in the general chat among hundreds of "successful deployments."
These are exactly the pain points Nightingale solves — an open-source monitoring system where alerting isn't just present, it's elevated to an art form.
What Is Nightingale?

Originally developed at Didi (the Chinese equivalent of Uber) and later open-sourced, Nightingale positions itself as the "alerting expert." If Grafana is the king of visualization, then Nightingale is the virtuoso of notifications.
The project's main highlight — not just collecting metrics, but intelligently processing alerts:
- Smart alert noise reduction
- Escalation of critical incidents
- 20+ built-in notification methods (from Slack to SMS)
- Self-healing capabilities (auto-remediation)
Top 5 Reasons to Try Nightingale
1. "Smart" Alerts That Won't Wake You Up for Nothing
Nightingale can:
- Group related incidents (e.g., 100 crashed pods in one cluster)
- Filter out false positives
- Automatically escalate priority of "stale" alerts
2. Flexible Notification Scenarios
Want to:
- First alert goes to Slack
- Repeat alert goes as SMS to the engineer
- Critical failure calls your phone?
Nightingale handles this through intuitive "notification rules" without writing scripts.
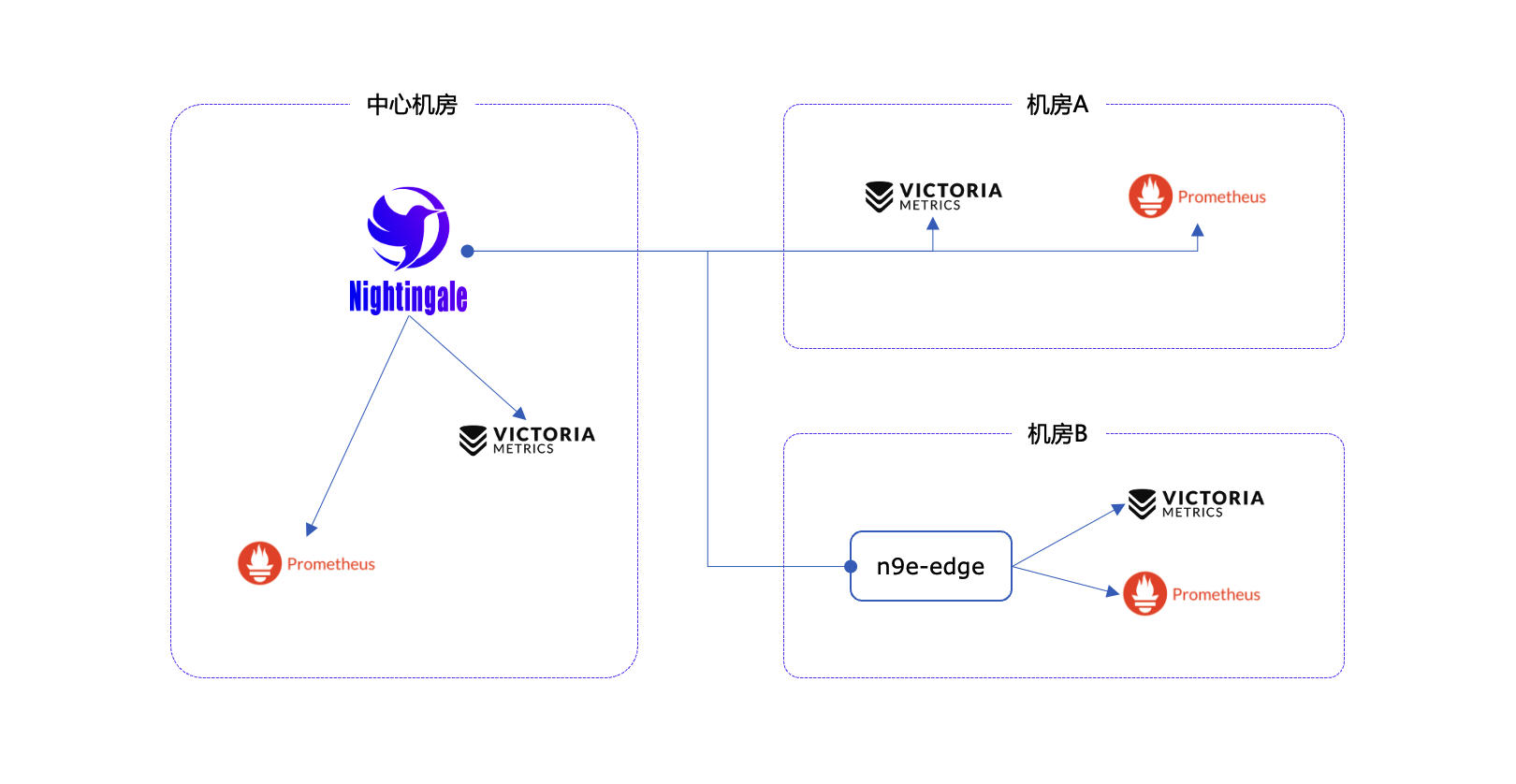
3. Works in Distributed Infrastructures
For edge locations with unstable internet, it offers mode — a local alerting engine that continues to work even when connection to the center is lost.
4. Ready-Made Dashboards and Rules
The project includes pre-installed:
- Dashboards for popular databases and middleware
- Alert rule templates (can be imported from Prometheus)
- Metric descriptions (so you don't have to guess what means)
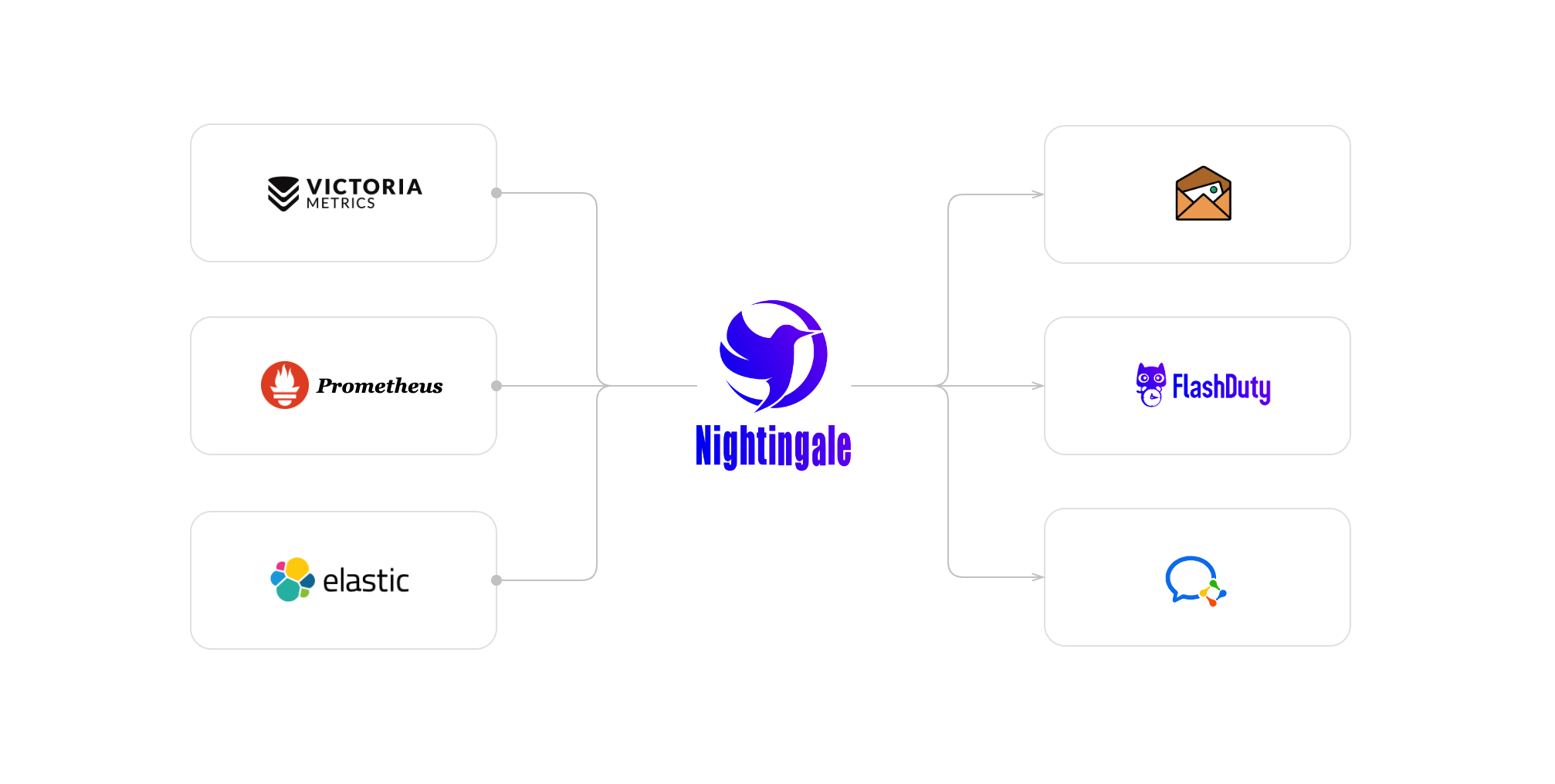
5. Integrates with Everything
- Data Sources: Prometheus, VictoriaMetrics, ElasticSearch, Loki, MySQL
- Protocols: Prometheus Remote Write, OpenTSDB, Datadog
- Agents: Recommended Categraf, but works with others too
How Does It Work Under the Hood?
Architecturally, Nightingale consists of:
- Alerting Core — evaluates rules, manages incident lifecycle
- Connectors — adapters to various metric storage systems
- Notification Engine — routes alerts according to defined rules
- API for integration with external systems
Written primarily in Go, which ensures good performance even under high load.
Who Will Find It Particularly Useful?
- Teams with distributed infrastructure — edge mode really saves the day
- Those tired of "alert spam" — the system actually knows how to filter noise
- Companies with compliance requirements — flexible role system and business groups
- Anyone already using Prometheus — integration is practically seamless
Limitations
Nightingale is not a silver bullet. For complex scenarios like:
- Full incident management
- On-call rotation
Developers honestly recommend specialized solutions like PagerDuty.
How to Get Started?
- Deploy the server (instructions)
- Connect your metrics collector (they recommend Categraf)
- Configure alerting rules through the web interface
For testing, you can use Docker images:
docker pull flashcatcloud/nightingale
Conclusion: Is It Worth Trying?
If you have:
-
10 servers
-
5 alerts per day
- At least one false alarm at night in the last month
— definitely yes. Nightingale will save your nerves and your team's nerves.
For smaller projects, it might be easier to stick with Prometheus Alertmanager + Grafana combo. But when alerting becomes a pain — this is the best open-source option we've seen.
P.S. The project is actively developing — over the last year, support for new storage systems has been added and work with edge devices has been improved. GitHub stars are growing rapidly:

Give it a try — maybe it's exactly the tool you've been missing.
Related projects