Cómo Recopilar Datos Sin Dolor Ni Código Usando Spider-flow
Imagina esto: necesitas recopilar datos de una docena de sitios web, procesarlos, limpiar el desorden y almacenarlos ordenadamente en una base de datos. Por lo general, esto significa horas escribiendo código en Python o Node.js, luchando con selectores, configurando proxies y depuración interminable. ¿Pero qué pasaría si te dijera que todo el proceso puede ser "dibujado" en un navegador, como un diagrama de flujo normal?
Hoy analizaremos Spider-flow — una potente plataforma basada en Java que convierte la creación de analizadores en programación visual. Este proyecto tiene más de 11 mil estrellas en GitHub, y definitivamente merece tu atención si valoras tu tiempo.
Qué es Spider-flow y por qué es conveniente
Spider-flow no es solo una biblioteca, sino un entorno de desarrollo completo (IDE) para analizadores. En lugar de escribir cientos de líneas de código, usas una interfaz gráfica. Arrastras y sueltas nodos, los conectas con líneas y configuras la lógica de operación.
¿Para quién será útil?
- Desarrolladores que necesitan crear rápidamente un prototipo o automatizar la recopilación de datos sin sumergirse en escribir código repetitivo.
- Analistas que quieren obtener datos por su cuenta sin esperar ayuda del equipo de backend.
- Cualquiera que esté cansado de mantener un zoológico de scripts de análisis.
Cinco razones para echarle un vistazo más de cerca a este proyecto
1. Control visual de la lógica
La característica principal es la interfaz de Flujo. Ves toda la ruta de los datos: desde la solicitud HTTP hasta escribir en la tabla. Esto hace que la depuración sea mucho más fácil. Si ocurre un error en alguna etapa, inmediatamente ves dónde se "rompió" la cadena.
2. Versatilidad en la extracción de datos
Spider-flow no te limita a una sola cosa. En un solo proyecto, puedes combinar:
- XPath y selectores CSS para HTML clásico.
- JsonPath para trabajar con APIs.
- Expresiones regulares para texto complejo.
- Formatos binarios si necesitas extraer algo específico.
3. Trabajo directo con bases de datos
Olvídate de los archivos CSV intermedios (aunque también son compatibles). La plataforma puede comunicarse con bases de datos SQL "de fábrica". Puedes ejecutar select, insert o update justo durante el proceso de análisis. Por ejemplo, verificar si un registro ya existe en la base de datos, y si no — agregarlo.
4. El contenido dinámico ya no es un problema
Muchos sitios web modernos están construidos con React o Vue, y no puedes obtenerlos con una solicitud GET normal. Spider-flow tiene un excelente plugin para Selenium que permite renderizar páginas JS y simular acciones reales del usuario.
5. Extensión flexible a través de plugins
El proyecto está construido sobre un principio modular. Si las funciones estándar no son suficientes, puedes conectar plugins para:
- Reconocimiento de captchas (OCR).
- Trabajo con Redis y MongoDB.
- Uso de pools de proxies.
- Envío de notificaciones por correo electrónico.
Cómo se ve en la realidad
La interfaz del sistema es concisa y funcional. Así es como se ve tu lista de "arañas":
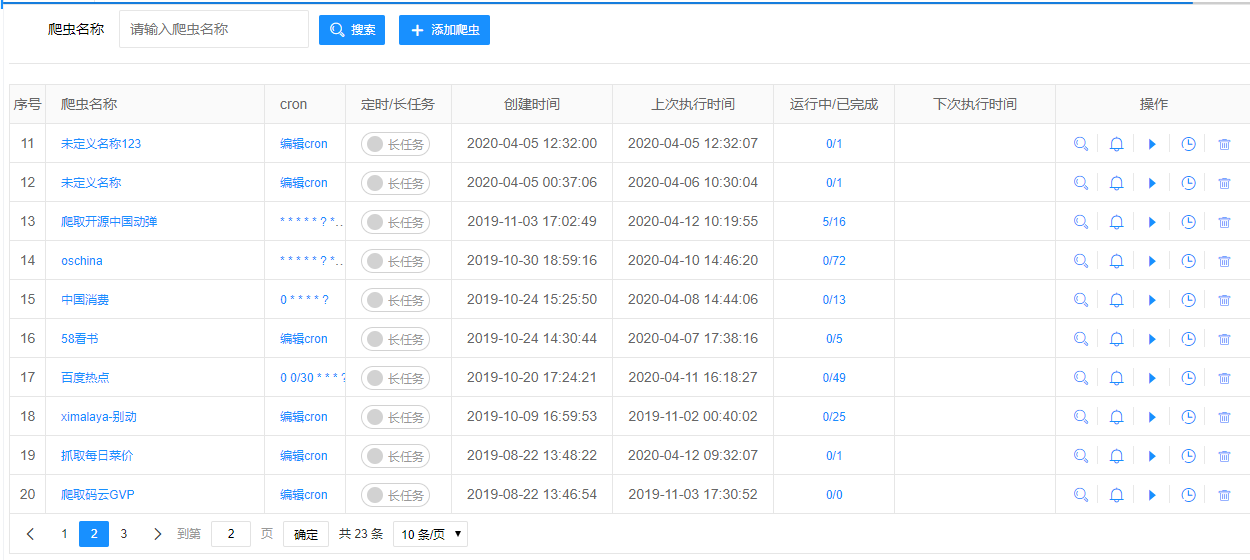
Y aquí está el proceso de prueba y depuración en tiempo real. Observa cómo se destacan claramente los pasos de ejecución:
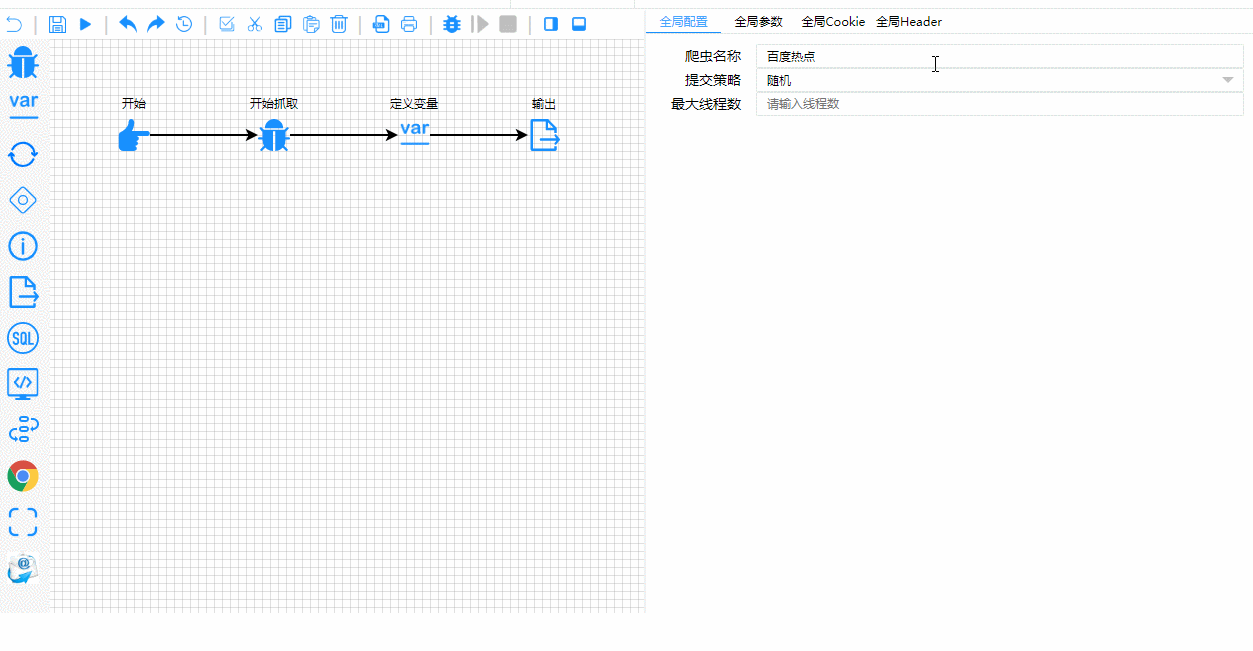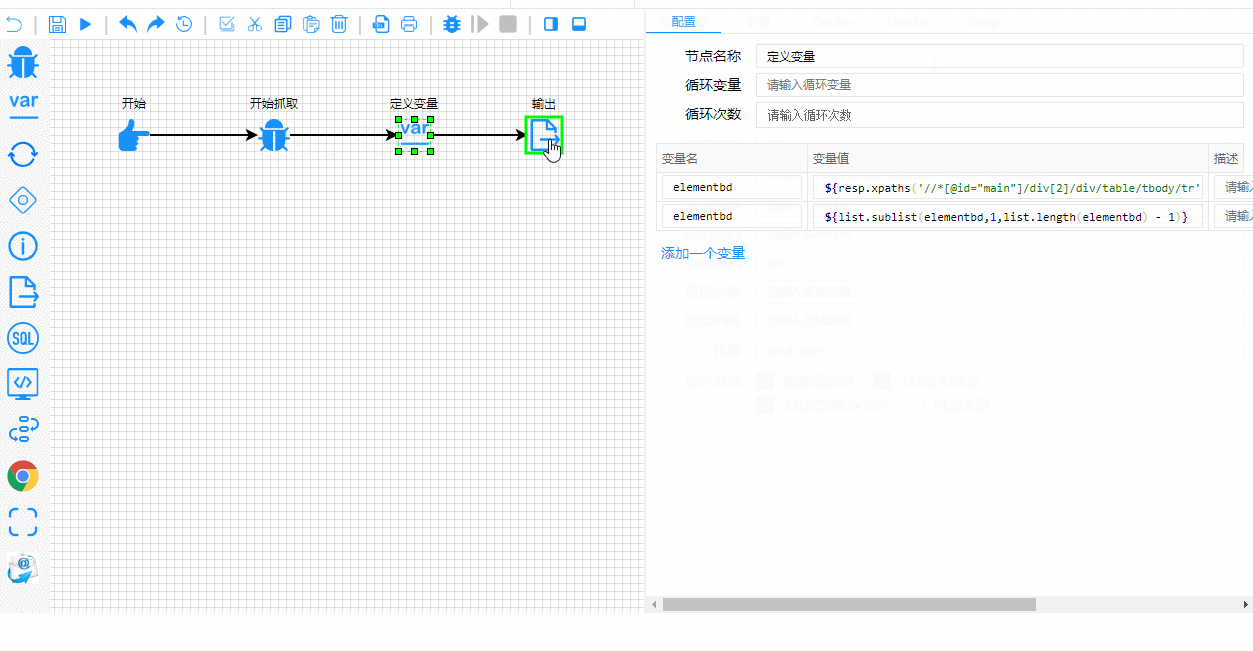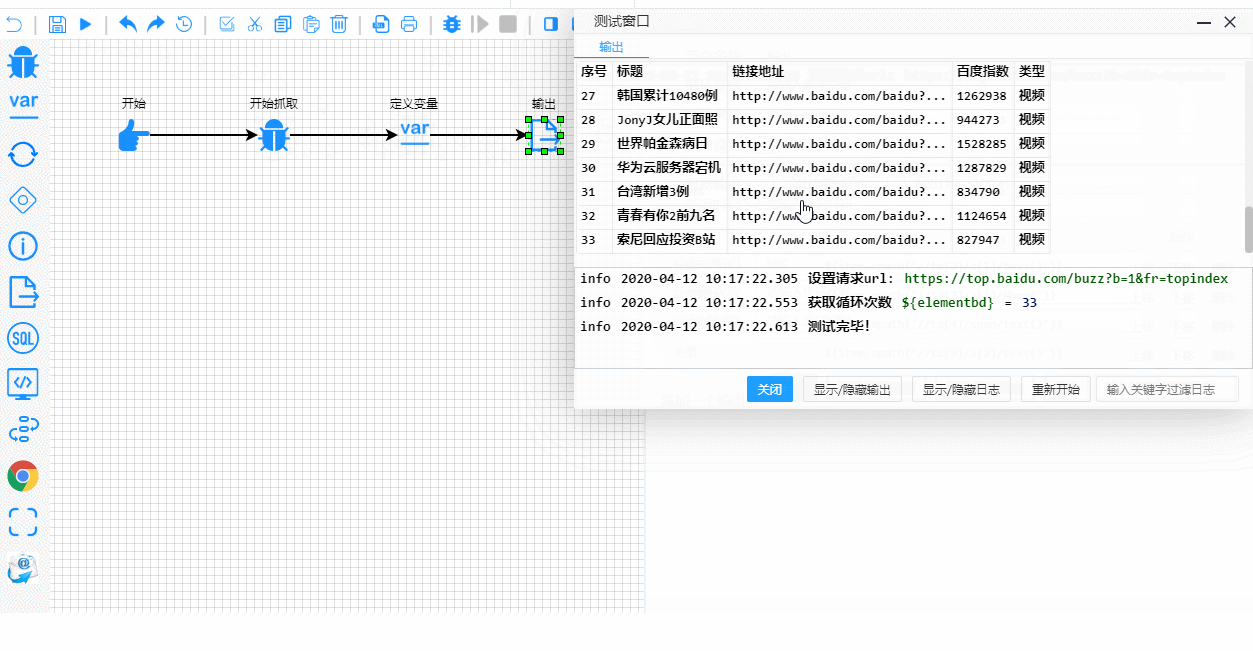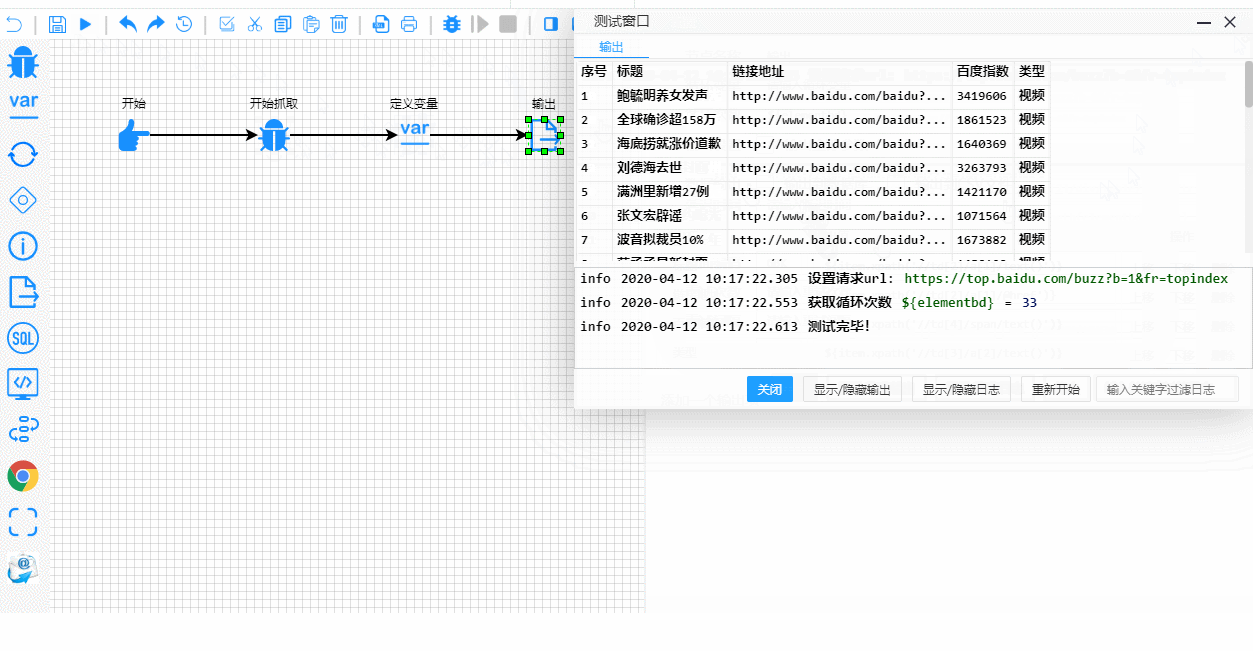
Detalles técnicos
Entre bastidores, Spider-flow utiliza una pila probada: Java 8+ y SpringBoot. Esto garantiza estabilidad y alto rendimiento. La plataforma soporta gestión automática de cookies, manejo de headers e incluso funciones JavaScript personalizadas si todavía quieres escribir un poco de código para transformaciones complejas de datos.
Para quienes quieran integrar Spider-flow en su ecosistema, se proporciona una API HTTP. Puedes activar tareas externamente o recuperar los resultados del trabajo a través de solicitudes.
Casos de uso prácticos
¿Dónde se mostrará mejor Spider-flow?
- Monitoreo de precios de competidores: Configura un flujo, agrega un pool de proxies y guarda los cambios de precios en la base de datos cada media hora.
- Agregadores de noticias: Recopilar datos de diferentes fuentes y llevarlos a un formato unificado a través de funciones integradas de procesamiento de cadenas y fechas.
- Llenado de tiendas en línea: Si un proveedor solo proporciona un sitio web sin API, Spider-flow ayudará a extraer descripciones de productos y descargar imágenes (hay un plugin para OSS).
¿Vale la pena probar?
Si tu trabajo involucra datos, entonces definitivamente sí. Spider-flow te gana al reducir la barrera de entrada para el web scraping, sin reducir las capacidades para profesionales. Es un gran ejemplo de cómo las herramientas low-code realmente pueden acelerar el desarrollo, en lugar de solo crear imágenes bonitas.
El proyecto es desarrollado activamente por la comunidad, tiene documentación detallada e incluso una demo donde puedes "jugar" con la interfaz antes de la instalación.
Enlaces útiles:
¡Intenta construir tu primer flujo, y es probable que no quieras volver a escribir analizadores manualmente!
Proyectos relacionados