如何使用 Spider-flow 无痛、无代码地采集数据
想象一下:你需要从十几个网站采集数据,处理它们,清理掉无用的内容,然后整齐地存储到数据库中。通常,这意味着你要花上几个小时用 Python 或 Node.js 编写代码,与选择器搏斗,配置代理,还要没完没了地调试。但如果我告诉你,整个过程可以在浏览器中"画"出来,就像普通的流程图一样呢?
今天我们要深入了解 Spider-flow —— 一个强大的基于 Java 的平台,将解析器创建变成可视化编程。这个项目在 GitHub 上拥有超过 1.1 万星标,如果你珍惜自己的时间,它绝对值得你关注。
什么是 Spider-flow,为什么它很方便
Spider-flow 不仅仅是一个库,而是一个完整的解析器开发环境(IDE)。你不需要编写数百行代码,而是使用图形界面。拖放节点,用线条连接它们,然后配置操作逻辑。
这会对谁有帮助?
- 开发者——需要快速勾勒原型或自动化数据采集,而不想深入编写样板代码。
- 分析师——想要自己获取数据,而不想等待后端团队的帮助。
- 所有人——厌倦了维护一堆解析脚本的人。
关注这个项目的五个理由
1. 可视化逻辑控制
主要特点是 Flow 界面。你可以看到整个数据路径:从 HTTP 请求到写入表格。这使得调试变得简单很多。如果某个阶段出现错误,你可以立即看到链在哪里"断开"了。
2. 数据提取的多样性
Spider-flow 不会限制你只做一件事。在一个项目中,你可以组合:
- 用于经典 HTML 的 XPath 和 CSS 选择器。
- 用于 API 工作的 JsonPath。
- 用于复杂文本的正则表达式。
- 如果你需要提取特定内容的二进制格式。
3. 直接操作数据库
忘掉中间 CSV 文件吧(虽然也支持)。该平台可以"开箱即用"地与 SQL 数据库通信。你可以在解析过程中执行 select、insert 或 update。例如,检查数据库中是否已存在某条记录,如果没有——则添加它。
4. 动态内容不再是问题
许多现代网站基于 React 或 Vue 构建,你无法用普通的 GET 请求获取它们。Spider-flow 有一个出色的 Selenium 插件,可以渲染 JS 页面并模拟真实用户操作。
5. 通过插件灵活扩展
该项目基于模块化原则构建。如果标准功能不够用,你可以连接插件用于:
- 验证码识别(OCR)。
- 使用 Redis 和 MongoDB。
- 使用代理池。
- 发送邮件通知。
实际使用效果
系统界面简洁而功能丰富。这是你看到的"爬虫"列表:
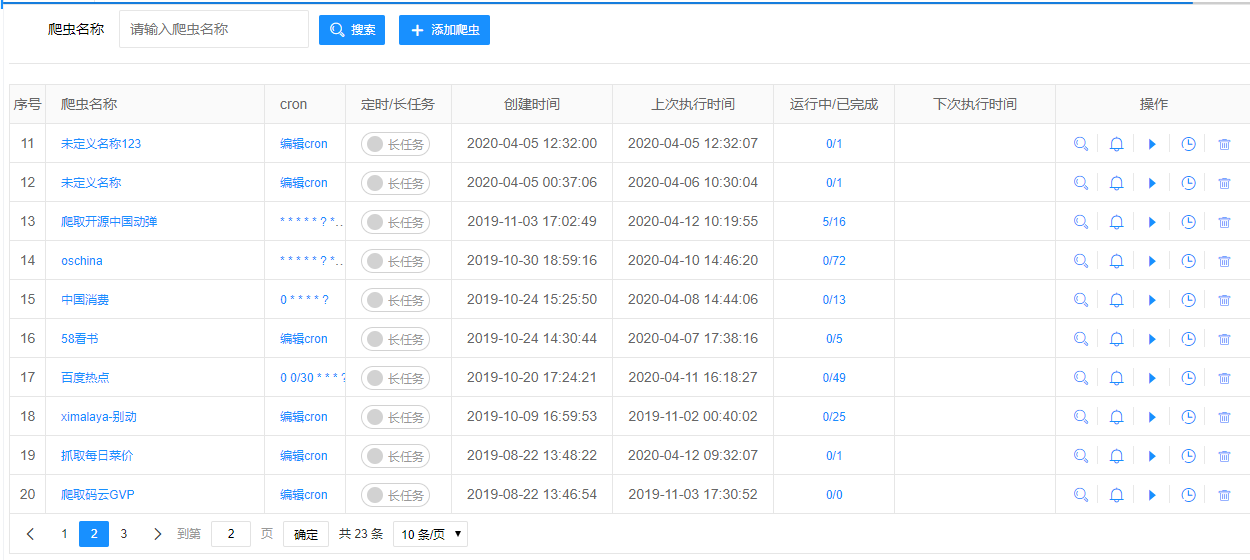
这是实时测试和调试过程。注意执行步骤的显示是多么清晰:
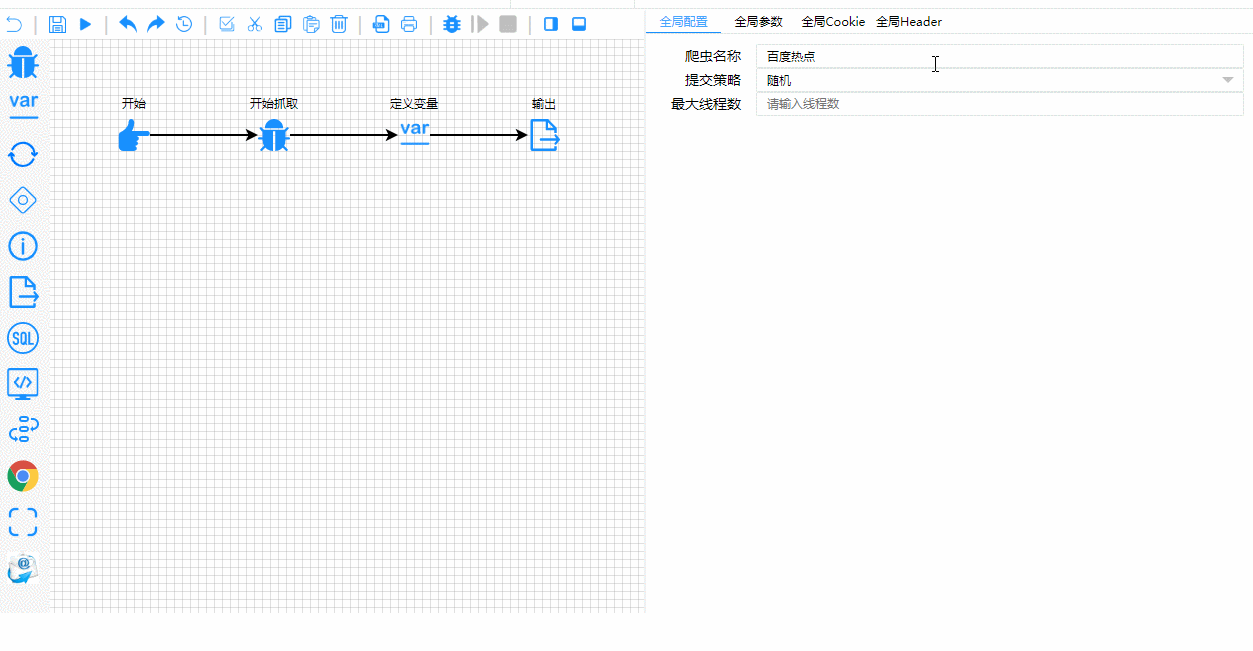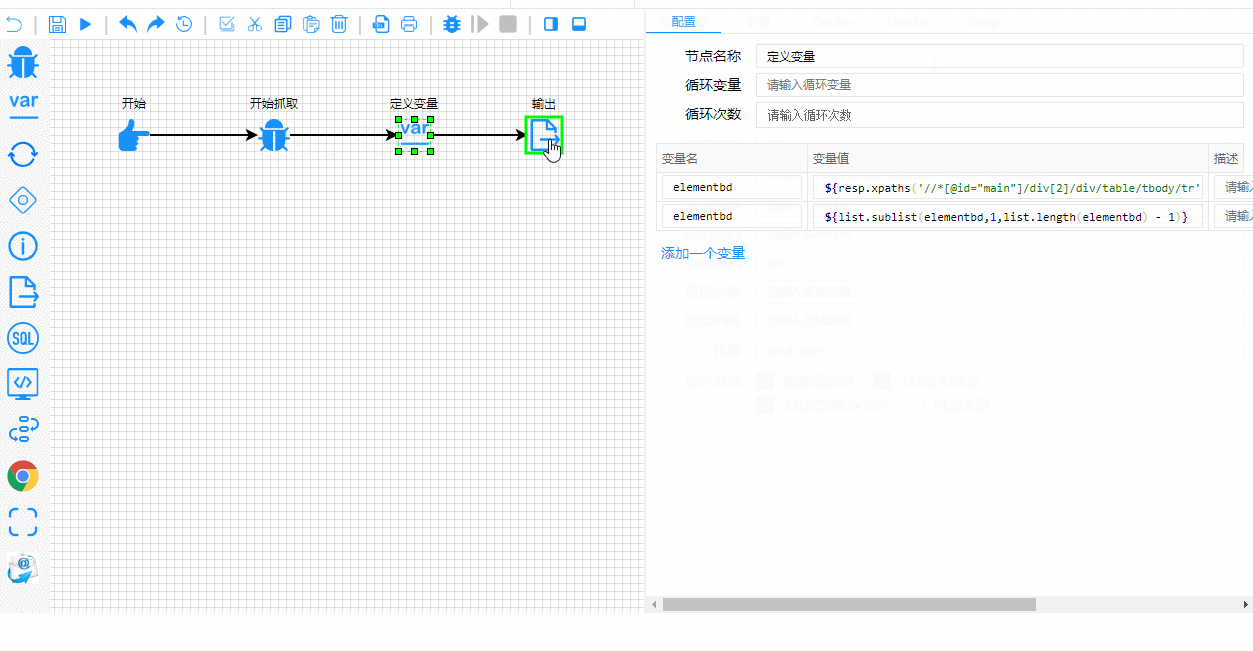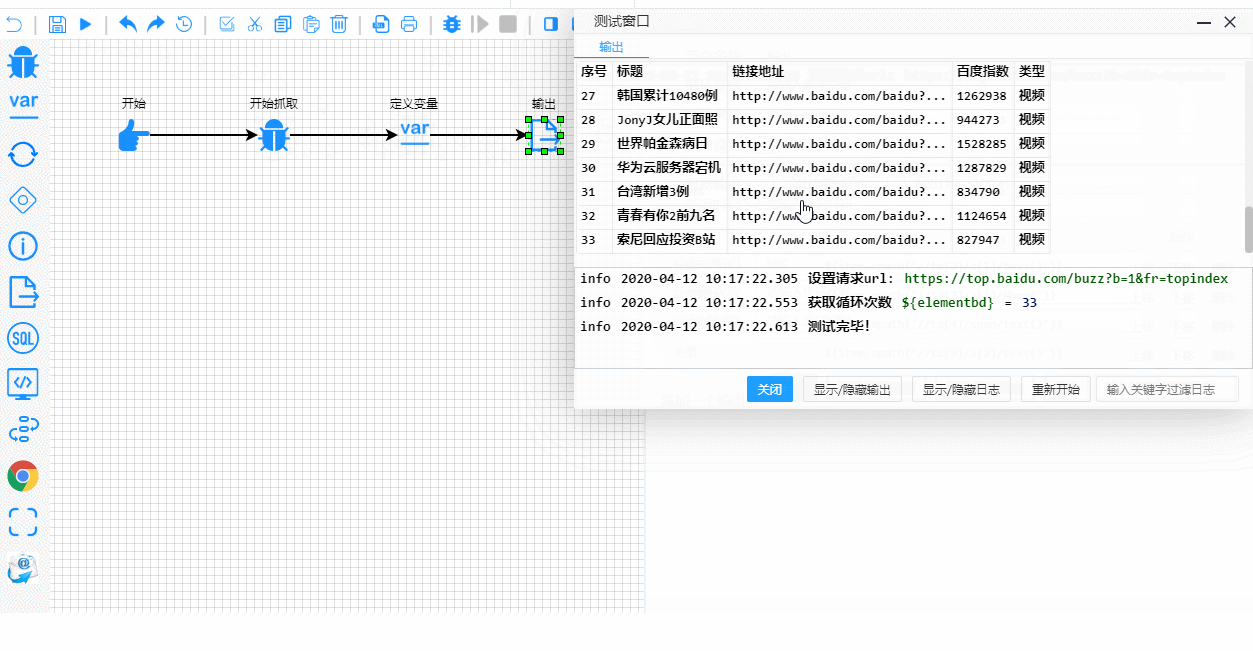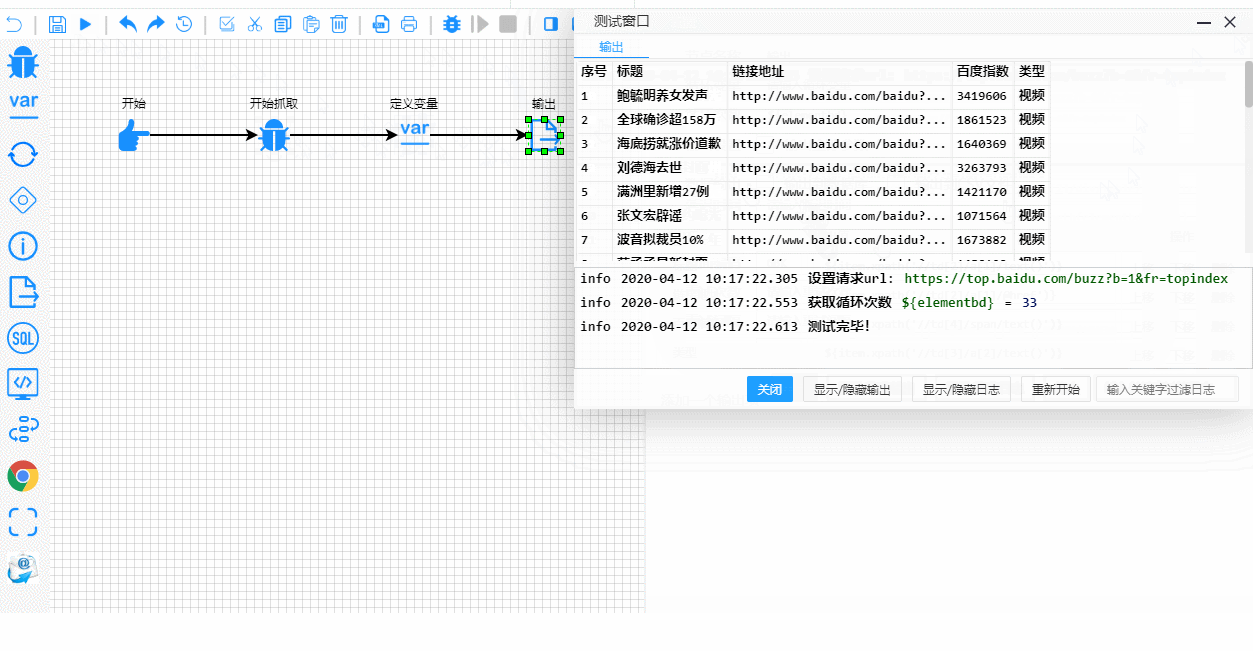
技术内幕
在底层,Spider-flow 使用成熟的技术栈:Java 8+ 和 SpringBoot。这确保了稳定性和高性能。该平台支持自动 Cookie 管理、请求头处理,甚至如果你仍然想为复杂数据转换编写少量代码,还支持自定义 JavaScript 函数。
对于想要将 Spider-flow 集成到自己生态系统中的人,提供了 HTTP API。你可以从外部触发任务或通过请求获取工作结果。
实际应用场景
Spider-flow 在哪些场景下表现最好?
- 竞品价格监控:设置一个流程,添加代理池,每半小时将价格变化保存到数据库。
- 新闻聚合器:从不同来源采集数据,通过内置的字符串和日期处理函数将其统一为一种格式。
- 填充在线商店:如果供应商只提供网站而没有 API,Spider-flow 可以帮助提取产品描述并下载图片(有用于 OSS 的插件)。
值得一试吗?
如果你的工作涉及数据,那答案绝对是肯定的。Spider-flow 降低了网页爬取的入门门槛,同时不会削减专业用户的能力。这是一个很好的例子,说明低代码工具实际上可以加速开发,而不仅仅是画出漂亮的图。
该项目由社区活跃开发,有详细的文档,甚至还有一个演示,你可以在安装前先"玩转"界面。
实用链接:
试着构建你的第一个流程吧,很有可能,你再也不想手动编写解析器了!
相关项目