Jak zbierać dane bez bólu i kodu za pomocą Spider-flow
Wyobraź sobie taką sytuację: musisz zebrać dane z kilkunastu stron internetowych, przetworzyć je, oczyścić z niepotrzebnych elementów i elegancko zapisać do bazy danych. Zazwyczaj oznacza to godziny pisania kodu w Pythonie lub Node.js, zmagania z selektorami, konfigurowanie proxy i niekończące się debugowanie. A co, jeśli powiem Ci, że cały proces można „narysować" w przeglądarce, tak jak zwykły schemat blokowy?
Dzisiaj przyjrzymy się bliżej Spider-flow — potężnej platformie opartej na Javie, która zamienia tworzenie parserów w programowanie wizualne. Ten projekt ma ponad 11 tysięcy gwiazdek na GitHub i zdecydowanie zasługuje na Twoją uwagę, jeśli cenisz swój czas.
Czym jest Spider-flow i dlaczego jest to wygodne
Spider-flow to nie tylko biblioteka, ale pełnowartościowe środowisko programistyczne (IDE) do tworzenia parserów. Zamiast pisać setki linii kodu, korzystasz z interfejsu graficznego. Przeciągasz i upuszczasz węzły, łączysz je liniami i konfigurujesz logikę działania.
Komu to się przyda?
- Programistom, którzy potrzebują szybko stworzyć prototyp lub zautomatyzować zbieranie danych bez zagłębiania się w pisanie szablonowego kodu.
- Analitykom, którzy chcą samodzielnie pozyskiwać dane bez czekania na pomoc zespołu backendowego.
- Wszystkim, którzy mają dość zarządzania zoo skryptów parsujących.
Pięć powodów, by przyjrzeć się temu projektowi
1. Wizualna kontrola logiki
Główną cechą jest interfejs przepływu. Widzisz całą ścieżkę danych: od żądania HTTP po zapis do tabeli. To znacznie ułatwia debugowanie. Jeśli wystąpi błąd na którymś etapie, od razu widzisz, gdzie łańcuch „pękł".
2. Uniwersalność w ekstrakcji danych
Spider-flow nie ogranicza Cię do jednej rzeczy. W jednym projekcie możesz łączyć:
- XPath i selektory CSS do klasycznego HTML.
- JsonPath do pracy z API.
- Wyrażenia regularne do złożonych tekstów.
- Formaty binarne, jeśli musisz wyodrębnić coś konkretnego.
3. Bezpośrednia praca z bazami danych
Zapomnij o pośrednich plikach CSV (choć są obsługiwane). Platforma może komunikować się z bazami danych SQL „out of the box". Możesz wykonywać select, insert lub update bezpośrednio podczas procesu parsowania. Na przykład sprawdzić, czy rekord już istnieje w bazie danych, a jeśli nie — dodać go.
4. Dynamiczna zawartość nie jest już problemem
Wiele nowoczesnych stron internetowych jest zbudowanych na React lub Vue i nie można ich pobrać zwykłym żądaniem GET. Spider-flow ma doskonałą wtyczkę dla Selenium, która umożliwia renderowanie stron JS i symulowanie prawdziwych działań użytkownika.
5. Elastyczne rozszerzanie przez wtyczki
Projekt jest zbudowany na zasadzie modułowej. Jeśli standardowe funkcje nie są wystarczające, możesz podłączyć wtyczki do:
- Rozpoznawania captcha (OCR).
- Pracy z Redis i MongoDB.
- Korzystania z pul proxy.
- Wysyłania powiadomień e-mail.
Jak to wygląda w rzeczywistości
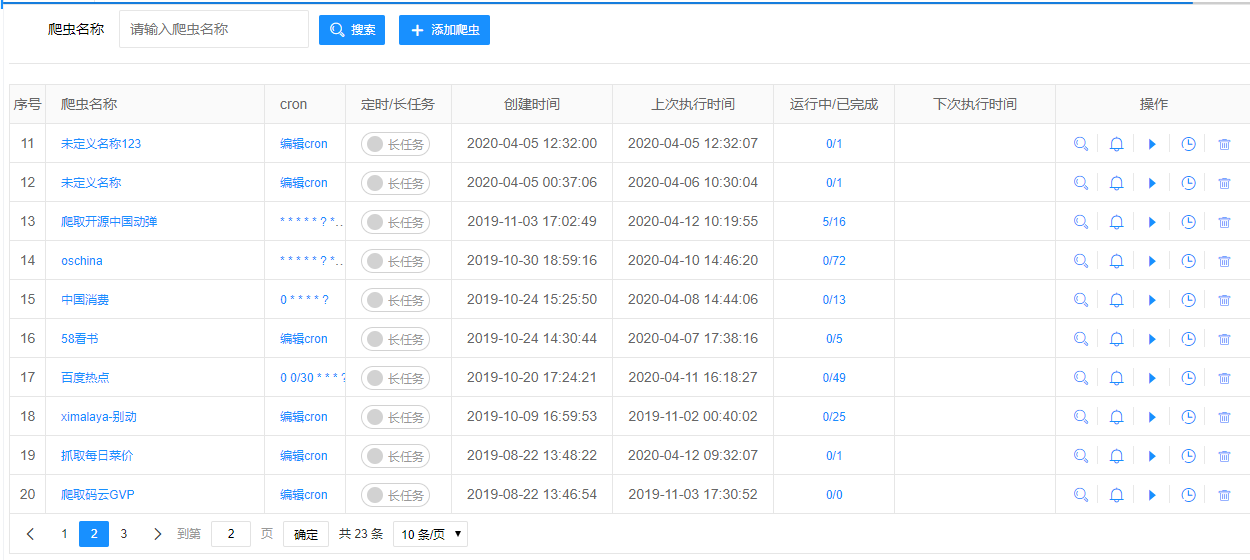
Interfejs systemu jest zwięzły i funkcjonalny. Oto jak wygląda lista Twoich „pająków":
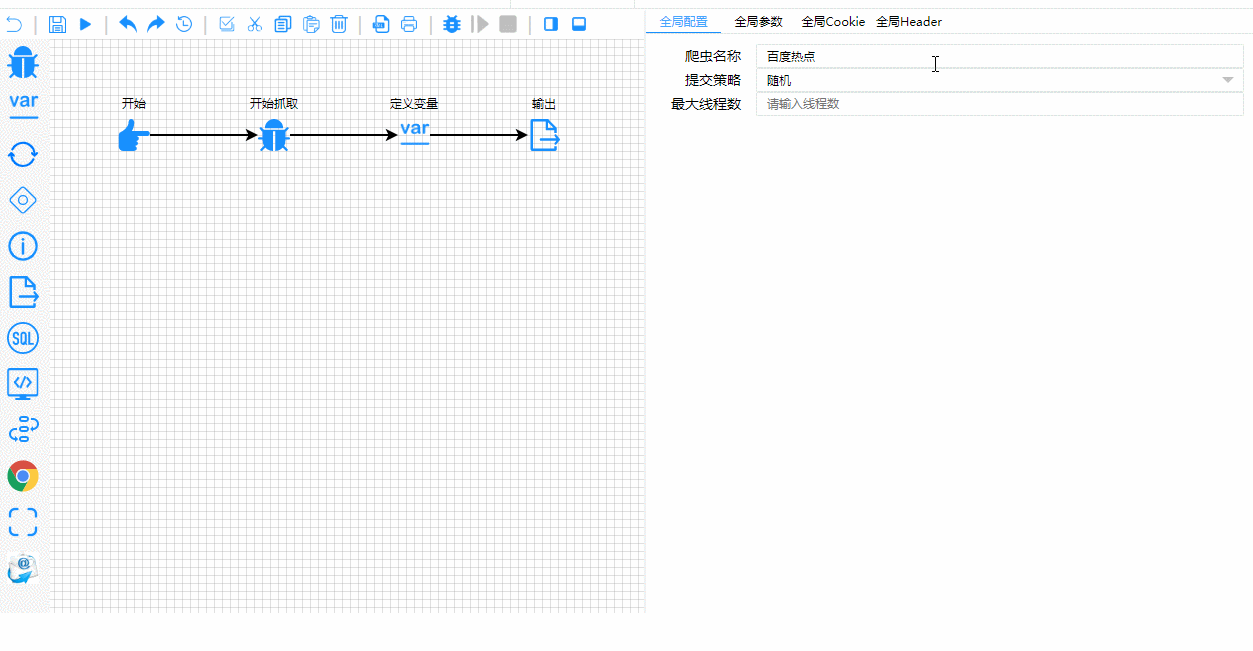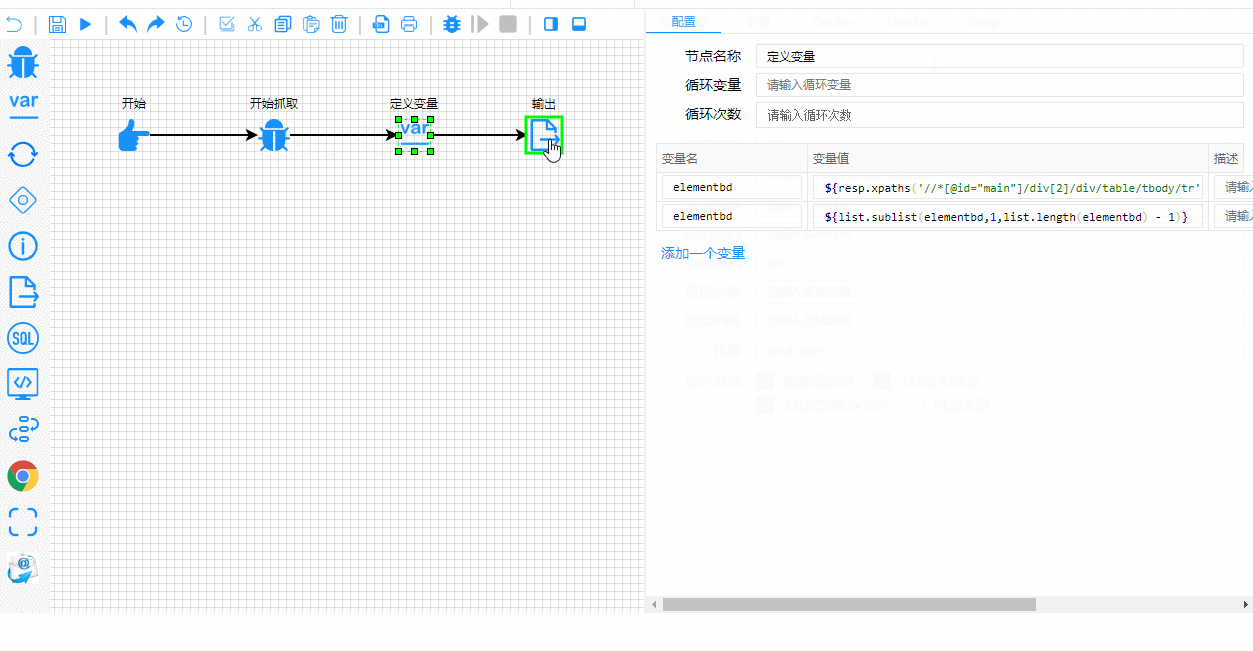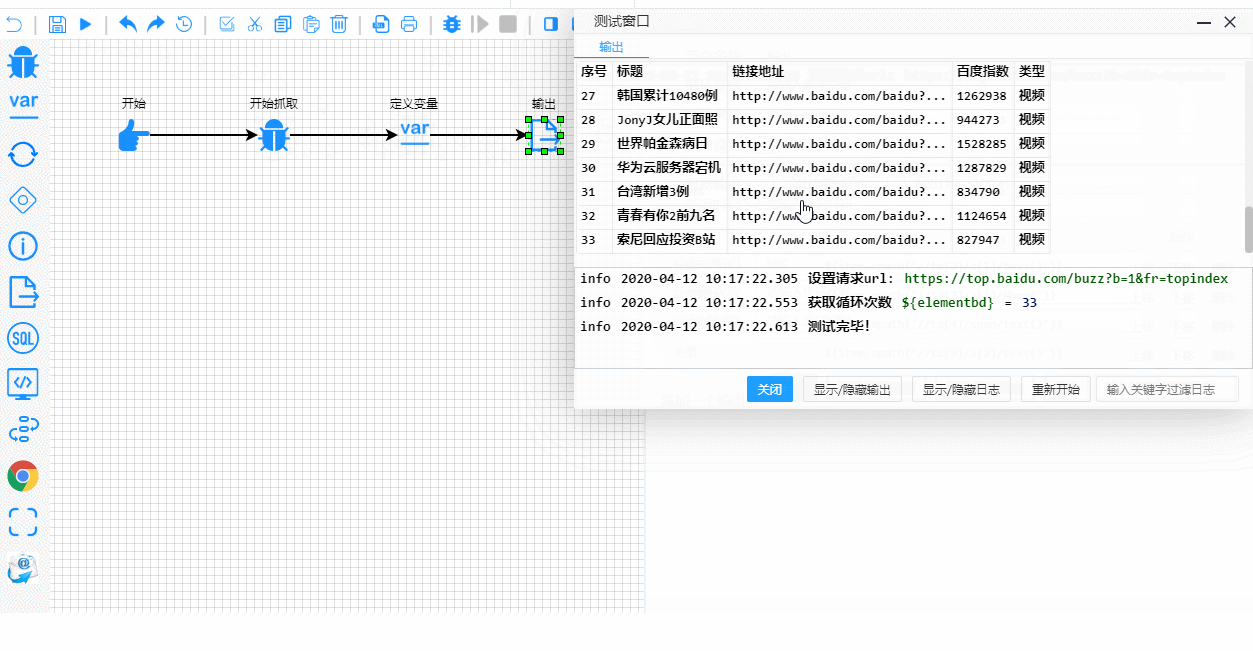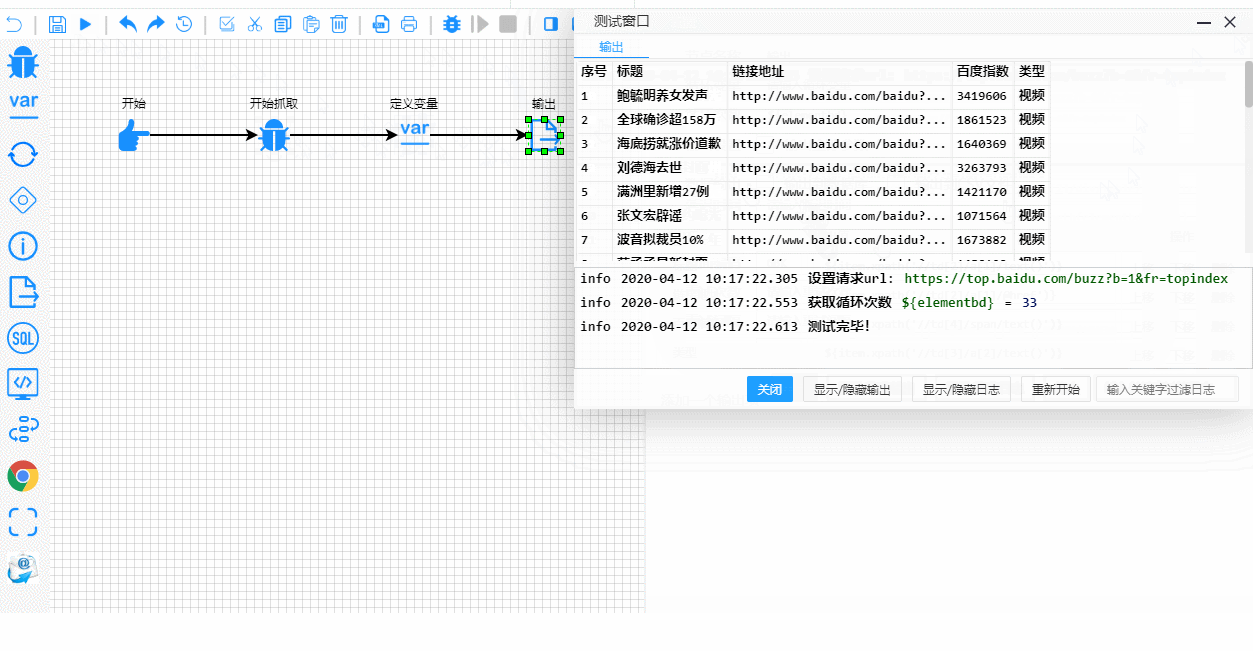
A tutaj masz proces testowania i debugowania w czasie rzeczywistym. Zwróć uwagę, jak wyraźnie podświetlone są etapy wykonania:
Szczegóły techniczne
Pod maską Spider-flow wykorzystuje sprawdzony stos technologiczny: Java 8+ i SpringBoot. Zapewnia to stabilność i wysoką wydajność. Platforma obsługuje automatyczne zarządzanie ciasteczkami, obsługę nagłówków, a nawet niestandardowe funkcje JavaScript, jeśli nadal chcesz napisać trochę kodu do złożonej transformacji danych.
Dla tych, którzy chcą zintegrować Spider-flow ze swoim ekosystemem, udostępniono HTTP API. Możesz uruchamiać zadania zewnętrznie lub pobierać wyniki pracy przez żądania.
Praktyczne przypadki użycia
Gdzie Spider-flow sprawdzi się najlepiej?
- Monitorowanie cen konkurencji: Skonfiguruj przepływ, dodaj pulę proxy i zapisuj zmiany cen do bazy danych co pół godziny.
- Aglomeratory wiadomości: Zbieranie danych z różnych źródeł i sprowadzanie ich do ujednoliconego formatu za pomocą wbudowanych funkcji przetwarzania ciągów znaków i dat.
- Zapełnianie sklepów internetowych: Jeśli dostawca udostępnia tylko stronę internetową bez API, Spider-flow pomoże wyodrębnić opisy produktów i pobrać obrazy (jest wtyczka do OSS).
Czy warto wypróbować?
Jeśli Twoja praca wiąże się z danymi, to zdecydowanie tak. Spider-flow zdobywa Cię obniżeniem progu wejścia do web scrapingu, jednocześnie nie ograniczając możliwości dla profesjonalistów. To doskonały przykład na to, jak narzędzia low-code mogą faktycznie przyspieszyć rozwój, zamiast tylko tworzyć ładne obrazki.
Projekt jest aktywnie rozwijany przez społeczność, ma szczegółową dokumentację, a nawet demo, gdzie możesz „poeksperymentować" z interfejsem przed instalacją.
Przydatne linki:
Spróbuj zbudować swój pierwszy przepływ, a jest duża szansa, że nie będziesz chciał wracać do ręcznego pisania parserów!
Powiązane projekty