Como Coletar Dados Sem Dor ou Código Usando Spider-flow
Imagine isto: você precisa coletar dados de uma dúzia de sites, processá-los, limpar o que não serve e armazená-los neatly em um banco de dados. Geralmente, isso significa horas escrevendo código em Python ou Node.js, lutando com seletores, configurando proxies e depuração infinita. Mas e se eu dissesse que todo o processo pode ser "desenhado" em um navegador, assim como um fluxograma comum?
Hoje vamos analisar o Spider-flow — uma plataforma poderosa baseada em Java que transforma a criação de parsers em programação visual. Este projeto tem mais de 11 mil estrelas no GitHub, e definitivamente merece sua atenção se você valoriza seu tempo.
O que é Spider-flow e por que é conveniente
Spider-flow não é apenas uma biblioteca, mas um ambiente de desenvolvimento completo (IDE) para parsers. Em vez de escrever centenas de linhas de código, você usa uma interface gráfica. Você arrasta e solta nós, conecta-os com linhas e configura a lógica de operação.
Para quem isso será útil?
- Desenvolvedores que precisam rapidamente criar um protótipo ou automatizar a coleta de dados sem se aprofundar na escrita de boilerplate.
- Analistas que querem obter dados por conta própria sem esperar pela ajuda da equipe de backend.
- Todos que estão cansados de manter um zoológico de scripts de parsing.
Cinco razões para dar uma olhada mais de perto neste projeto
1. Controle Visual de Lógica
O recurso principal é a interface de Fluxo. Você vê todo o caminho dos dados: desde a requisição HTTP até a escrita na tabela. Isso torna a depuração muitas vezes mais fácil. Se ocorrer um erro em algum estágio, você imediatamente vê onde a cadeia "quebrou".
2. Versatilidade na Extração de Dados
Spider-flow não limita você a apenas uma coisa. Em um único projeto, você pode combinar:
- XPath e seletores CSS para HTML clássico.
- JsonPath para trabalhar com APIs.
- Expressões regulares para texto complexo.
- Formatos binários se você precisar extrair algo específico.
3. Trabalho Direto com Bancos de Dados
Esqueça arquivos CSV intermediários (embora sejam suportados). A plataforma pode se comunicar com bancos de dados SQL "out of the box". Você pode executar select, insert ou update durante o próprio processo de parsing. Por exemplo, verifique se um registro já existe no banco de dados, e se não — adicione-o.
4. Conteúdo Dinâmico Não é Mais um Problema
Muitos sites modernos são construídos com React ou Vue, e você não pode buscá-los com uma requisição GET comum. Spider-flow tem um excelente plugin para Selenium que permite renderizar páginas JS e simular ações reais de usuários.
5. Extensão Flexível Através de Plugins
O projeto é construído com um princípio modular. Se os recursos padrão não forem suficientes, você pode conectar plugins para:
- Reconhecimento de captcha (OCR).
- Trabalho com Redis e MongoDB.
- Uso de pools de proxies.
- Envio de notificações por email.
Como é na Realidade
A interface do sistema é concisa e funcional. Aqui está como sua lista de "spiders" se parece:
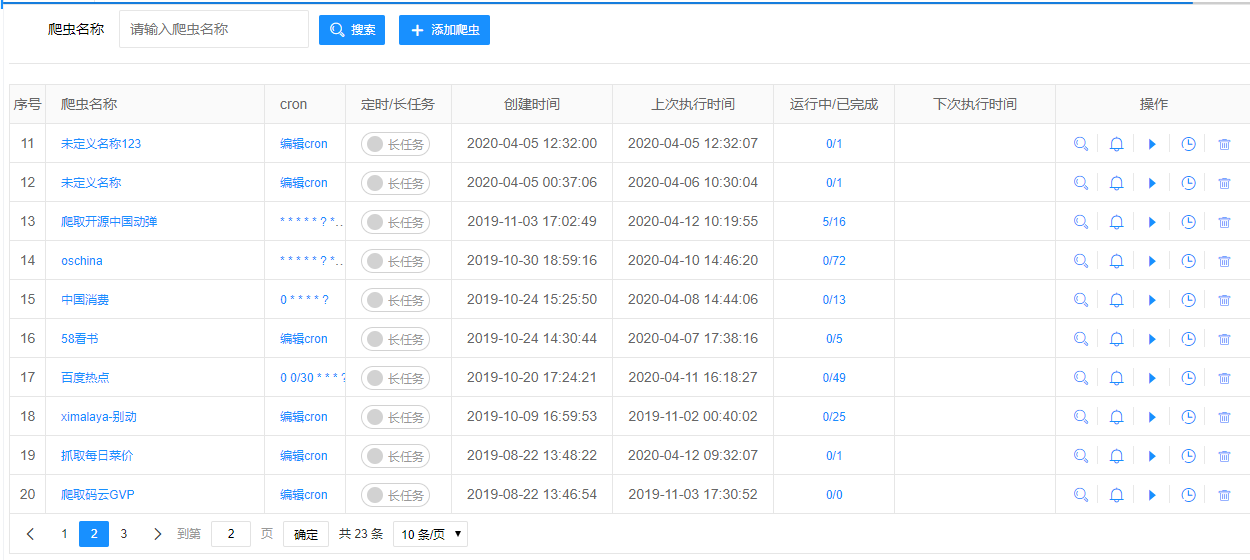
E aqui está o processo de teste e depuração em tempo real. Observe como os passos de execução são claramente destacados:
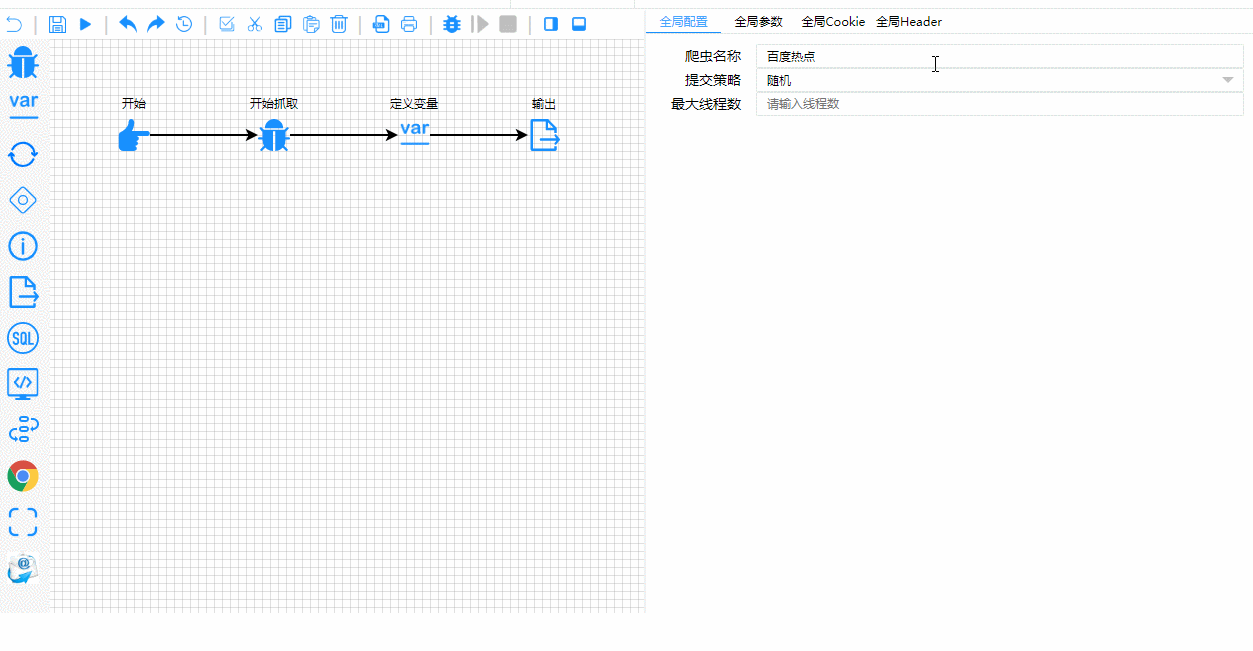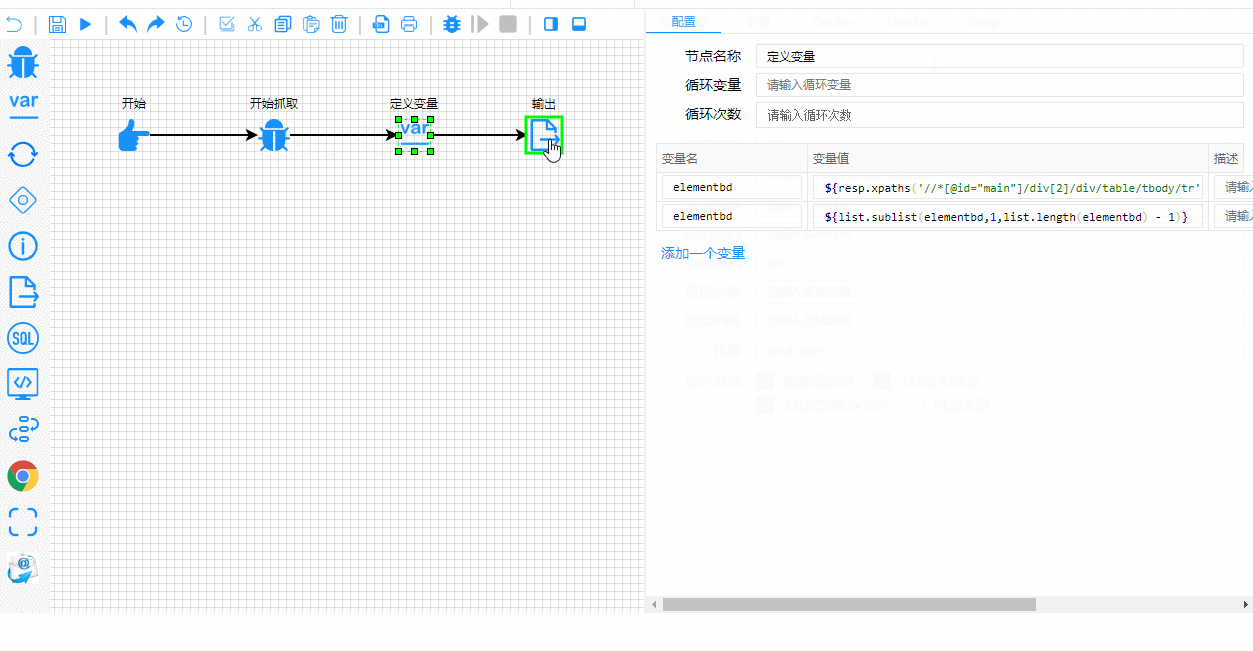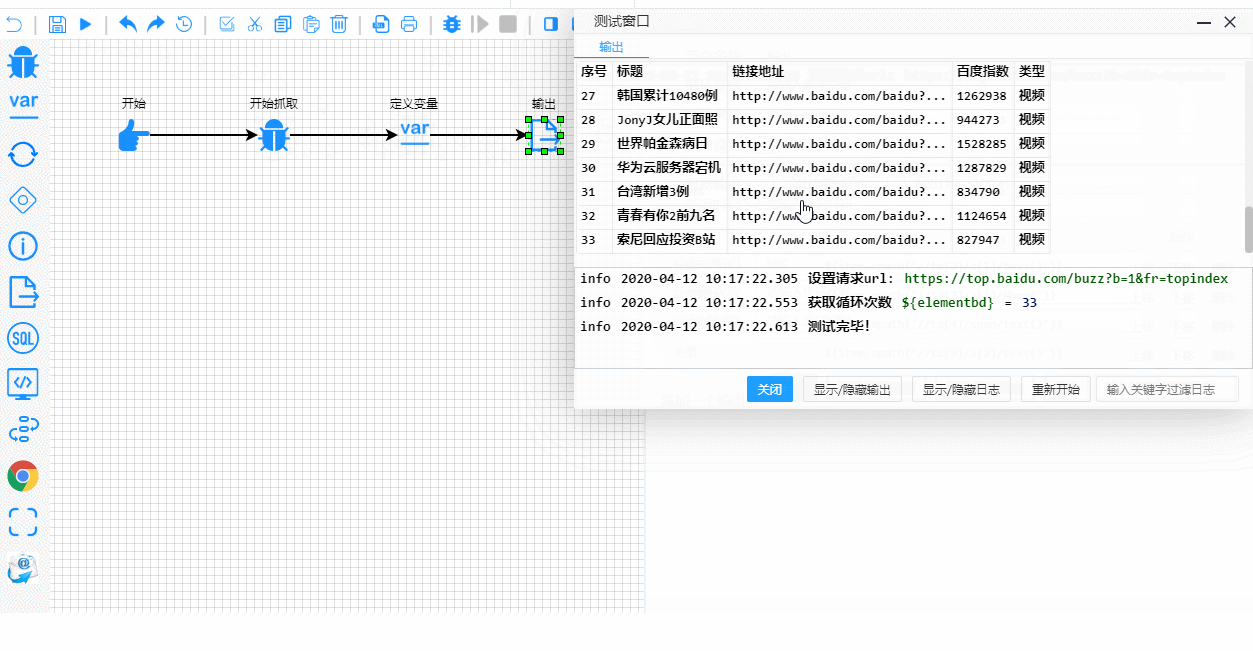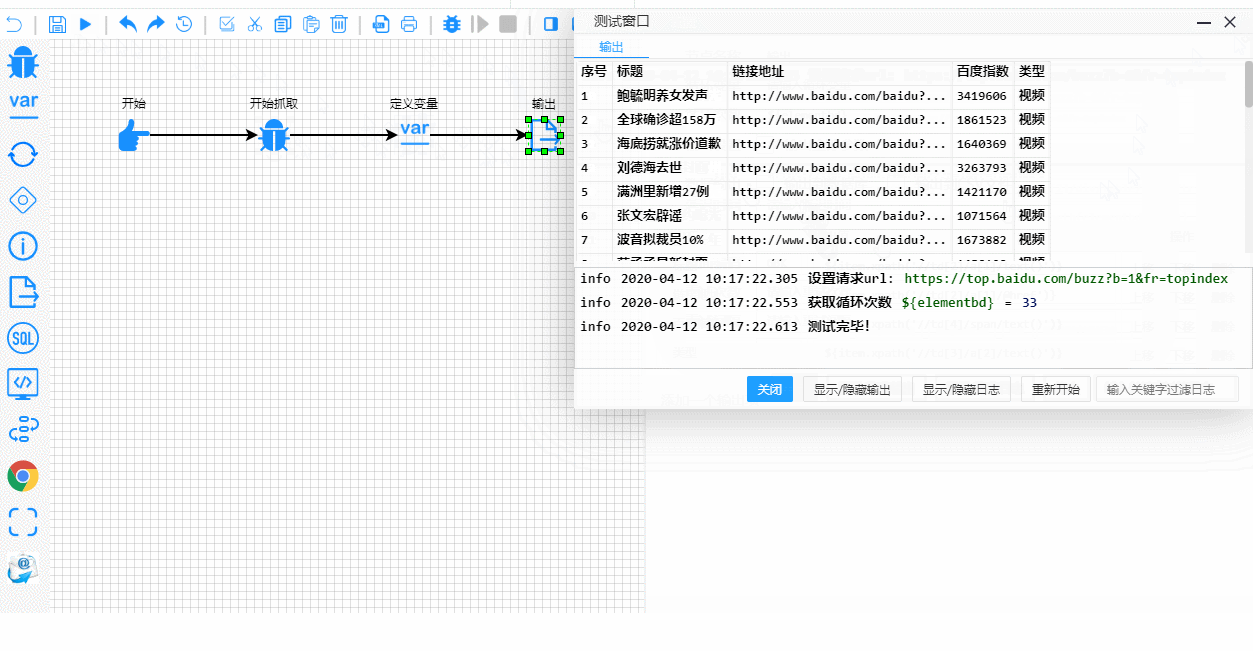
Detalhes Técnicos
Por baixo do capô, Spider-flow usa uma stack comprovada: Java 8+ e SpringBoot. Isso garante estabilidade e alto desempenho. A plataforma suporta gerenciamento automático de Cookies, manipulação de headers e até funções JavaScript personalizadas se você ainda quiser escrever um pouco de código para transformação complexa de dados.
Para quem deseja integrar Spider-flow ao seu ecossistema, é fornecida uma API HTTP. Você pode acionar tarefas externamente ou recuperar resultados de trabalho através de requisições.
Casos de Uso Práticos
Onde o Spider-flow mostrará seu melhor desempenho?
- Monitoramento de preços de concorrentes: Configure um fluxo, adicione um pool de proxies e salve as mudanças de preços no banco de dados a cada meia hora.
- Agregadores de notícias: Coletar dados de diferentes fontes e trazê-los a um formato unificado através de funções integradas de processamento de strings e datas.
- Preenchimento de lojas online: Se um fornecedor fornece apenas um site sem API, Spider-flow ajudará a extrair descrições de produtos e baixar imagens (há um plugin para OSS).
Vale a Pena Experimentar?
Se seu trabalho envolve dados, então definitivamente sim. Spider-flow conquista você ao diminuir a barreira de entrada para web scraping, sem cortar recursos para profissionais. É um ótimo exemplo de como ferramentas low-code podem realmente acelerar o desenvolvimento, em vez de apenas criar imagens bonitas.
O projeto é ativamente desenvolvido pela comunidade, tem documentação detalhada e até mesmo um demo onde você pode "brincar" com a interface antes da instalação.
Links úteis:
Experimente construir seu primeiro fluxo, e provavelmente você não vai querer voltar a escrever parsers manualmente!
Projetos relacionados