Comment collecter des données sans douleur ni code avec Spider-flow
Imaginez ceci : vous devez collecter des données sur une douzaine de sites web, les traiter, nettoyer les indésirables et les stocker proprement dans une base de données. Habituellement, cela signifie des heures d'écriture de code en Python ou Node.js, de lutte avec les sélecteurs, de configuration de proxies et de débogage sans fin. Mais si je vous disais que l'ensemble du processus peut être « dessiné » dans un navigateur, comme un organigramme classique ?
Aujourd'hui, nous allons décortiquer Spider-flow — une puissante plateforme basée sur Java qui transforme la création de parseurs en programmation visuelle. Ce projet compte plus de 11 000 étoiles sur GitHub, et il mérite définitivement votre attention si vous accorsez de la valeur à votre temps.
Qu'est-ce que Spider-flow et pourquoi c'est pratique
Spider-flow n'est pas qu'une simple bibliothèque, mais un environnement de développement complet (IDE) pour les parseurs. Au lieu d'écrire des centaines de lignes de code, vous utilisez une interface graphique. Vous glissez-déposez des nœuds, les connectez avec des lignes et configurez la logique de fonctionnement.
À qui cela sera-t-il utile ?
- Les développeurs qui ont besoin de prototyper rapidement ou d'automatiser la collecte de données sans se plonger dans l'écriture de code répétitif.
- Les analystes qui souhaitent obtenir des données par eux-mêmes sans attendre l'aide de l'équipe backend.
- Tout le monde qui en a marre de maintenir un zoo de scripts de parsing.
Cinq raisons de s'y pencher de plus près
1. Contrôle visuel de la logique
La fonctionnalité principale est l'interface Flow. Vous voyez l'ensemble du parcours des données : de la requête HTTP à l'écriture dans le tableau. Cela rend le débogage beaucoup plus facile. Si une erreur se produit à une étape donnée, vous voyez immédiatement où la chaîne s'est « cassée ».
2. Polyvalence dans l'extraction de données
Spider-flow ne vous limite pas à une seule chose. Dans un seul projet, vous pouvez combiner :
- XPath et les sélecteurs CSS pour le HTML classique.
- JsonPath pour travailler avec les APIs.
- Les expressions régulières pour les textes complexes.
- Les formats binaires si vous devez extraire quelque chose de spécifique.
3. Travail direct avec les bases de données
Oubliez les fichiers CSV intermédiaires (bien qu'ils soient pris en charge). La plateforme peut communiquer avec les bases de données SQL « out of the box ». Vous pouvez exécuter select, insert ou update directement pendant le processus de parsing. Par exemple, vérifiez si un enregistrement existe déjà dans la base de données, et sinon — ajoutez-le.
4. Le contenu dynamique n'est plus un problème
De nombreux sites web modernes sont construits avec React ou Vue, et vous ne pouvez pas les récupérer avec une simple requête GET. Spider-flow dispose d'un excellent plugin pour Selenium qui permet de rendre les pages JS et de simuler de vraies actions utilisateur.
5. Extension flexible via les plugins
Le projet est construit sur un principe modulaire. Si les fonctionnalités standard ne suffisent pas, vous pouvez connecter des plugins pour :
- La reconnaissance de captchas (OCR).
- Travailler avec Redis et MongoDB.
- Utiliser des pools de proxies.
- Envoyer des notifications par e-mail.
À quoi cela ressemble dans la réalité
L'interface du système est épurée et fonctionnelle. Voici à quoi ressemble votre liste d'« araignées » :
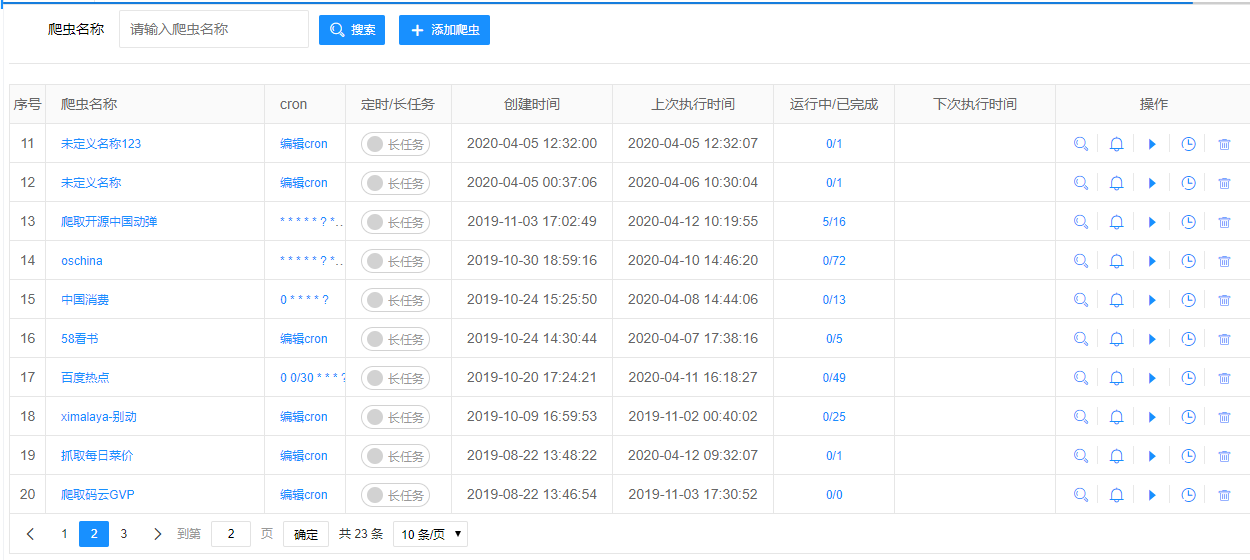
Et voici le processus de test et de débogage en temps réel. Remarquez à quel point les étapes d'exécution sont clairement mises en évidence :
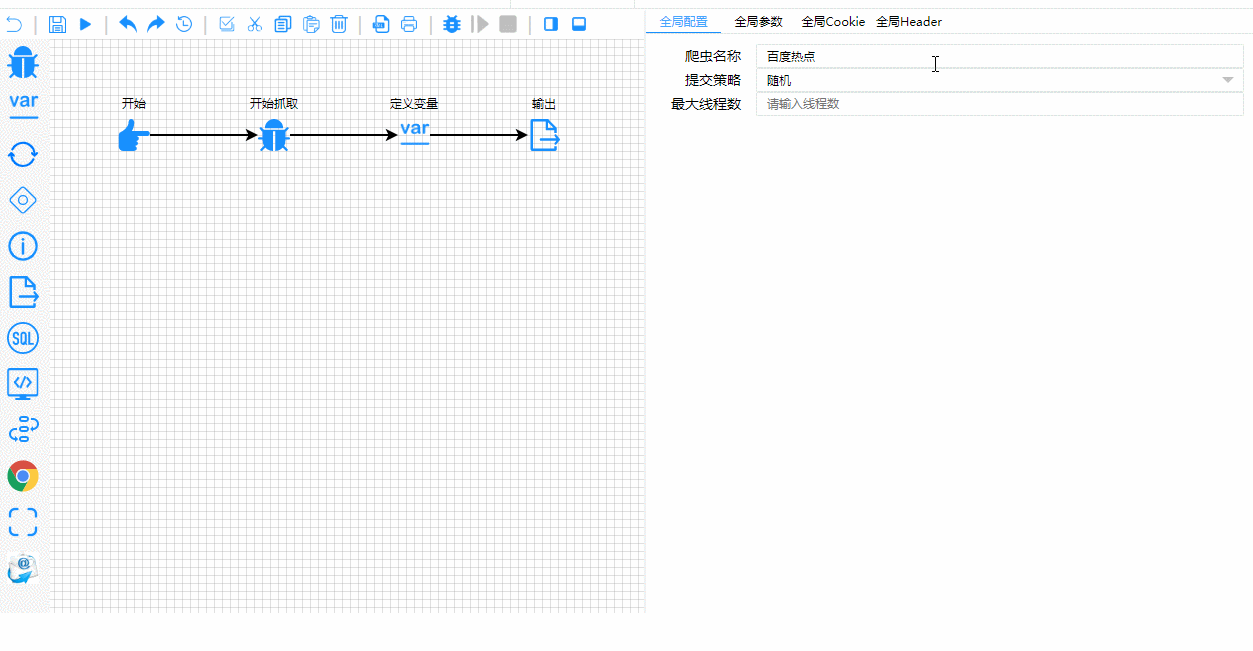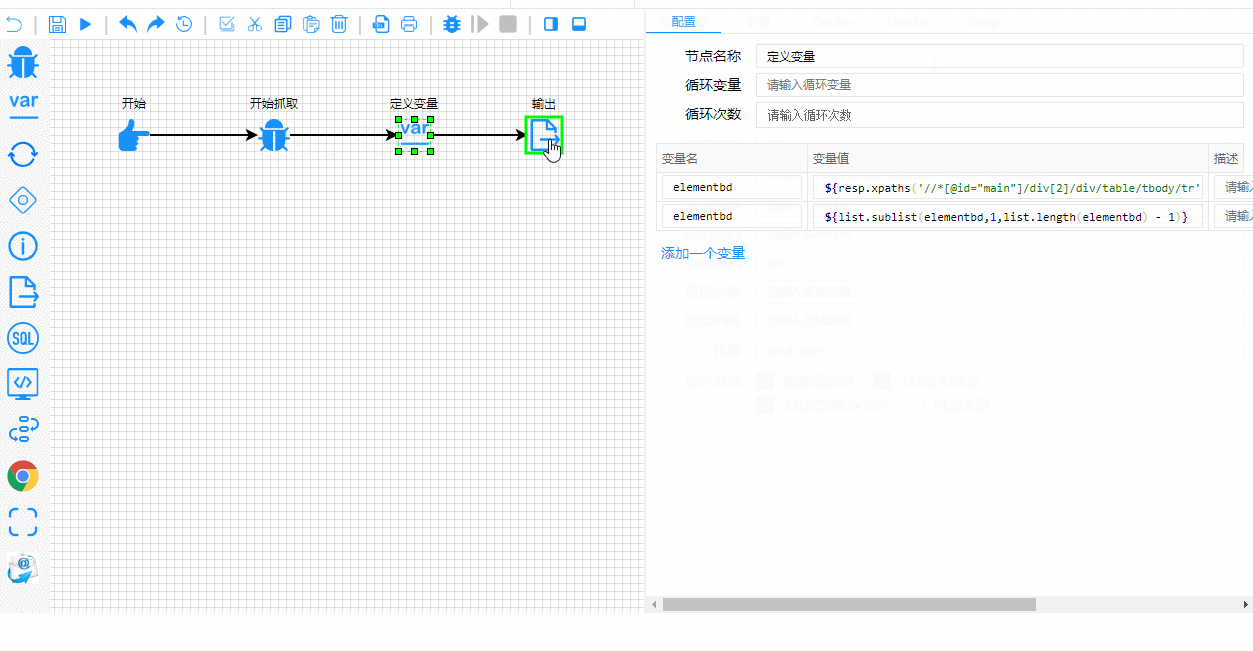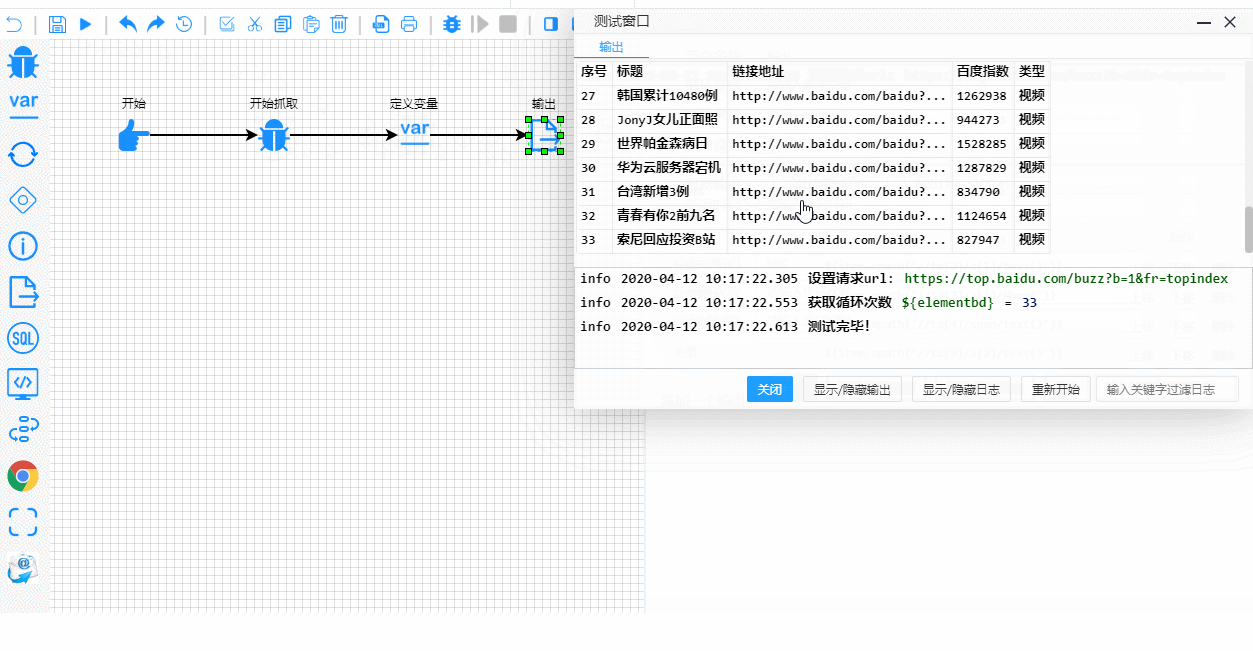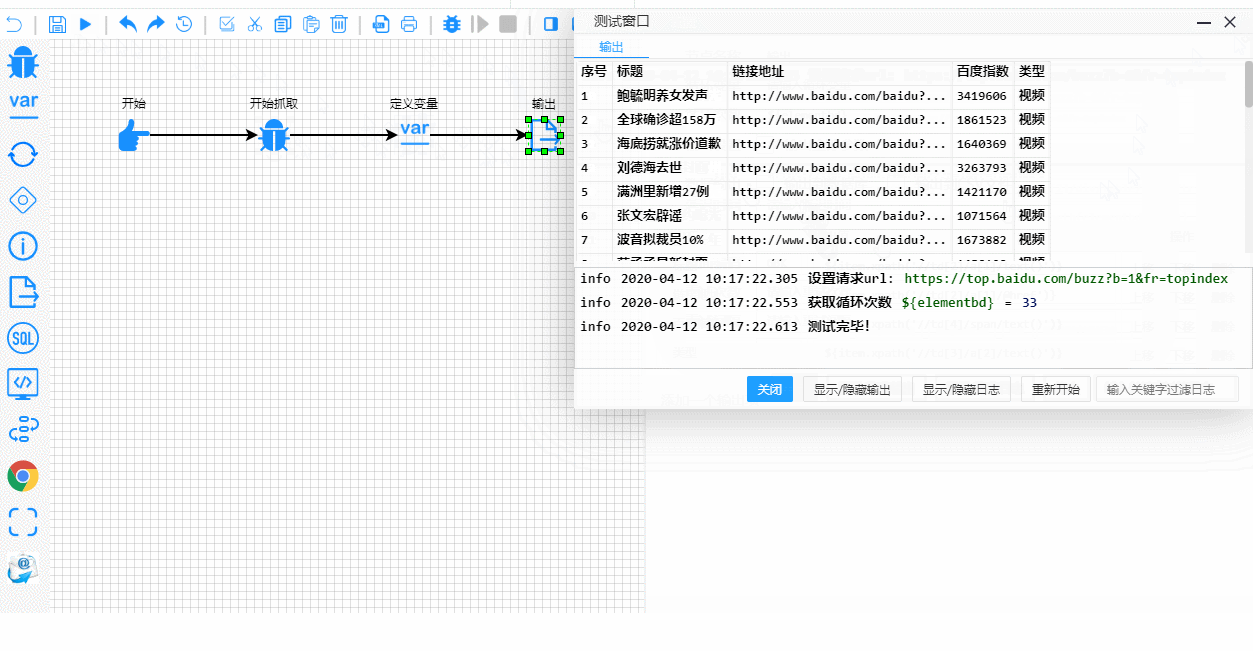
Les rouages techniques
Sous le capot, Spider-flow utilise une pile éprouvée : Java 8+ et SpringBoot. Cela garantit stabilité et haute performance. La plateforme prend en charge la gestion automatique des cookies, la manipulation des headers, et même les fonctions JavaScript personnalisées si vous souhaitez toujours écrire un peu de code pour des transformations de données complexes.
Pour ceux qui souhaitent intégrer Spider-flow dans leur écosystème, une API HTTP est fournie. Vous pouvez déclencher des tâches de l'extérieur ou récupérer les résultats du travail via des requêtes.
Cas d'utilisation pratiques
Où Spider-flow se révélera-t-il le mieux ?
- Surveillance des prix des concurrents : Configurez un flux, ajoutez un pool de proxies et enregistrez les changements de prix dans la base de données toutes les demi-heures.
- Agrégateurs d'actualités : Collecter des données de différentes sources et les mettre dans un format unifié grâce aux fonctions intégrées de traitement de chaînes et de dates.
- Remplissage de boutiques en ligne : Si un fournisseur ne propose qu'un site web sans API, Spider-flow vous aidera à extraire les descriptions de produits et à télécharger les images (il existe un plugin pour OSS).
Cela vaut-il la peine d'essayer ?
Si votre travail implique des données, alors certainement oui. Spider-flow vous conquiert en abaissant la barrière d'entrée pour le web scraping, tout en ne réduisant pas les capacités pour les professionnels. C'est un excellent exemple de la façon dont les outils low-code peuvent réellement accélérer le développement, plutôt que de créer de simples images attrayantes.
Le projet est activement développé par la communauté, dispose d'une documentation détaillée, et même d'une démo où vous pouvez « jouer » avec l'interface avant l'installation.
Liens utiles :
Essayez de construire votre premier flux, et il y a de fortes chances que vous n'ayez plus envie de revenir à l'écriture manuelle de parseurs !
Projets similaires