IndexTTS2: Wenn synthetisierte Sprache wirklich natürlich klingt
Stellen Sie sich vor: Sie müssen ein Video vertonen, bei dem jedes Wort präzise mit den Lippenbewegungen des Schauspielers übereinstimmen muss. Oder einen Sprachassistenten erstellen, der Text nicht nur mechanisch vorliest, sondern echte Emotionen vermittelt. Mit herkömmlichen TTS-Systemen war dies nahezu unmöglich – bis IndexTTS2 появился.
Was ist IndexTTS2?
IndexTTS2 ist ein Open-Source-Sprachsynthesemodell der nächsten Generation mit autoregressiver Architektur, entwickelt von einem Team aus China. Das Projekt hat bereits fast 10.000 Sterne auf GitHub gesammelt, und das aus gutem Grund.
Der Hauptvorteil? IndexTTS2 löst zwei zentrale Probleme moderner TTS-Systeme:
- Präzise Dauerkontrolle — jetzt können Sie Sprache mit Video synchronisieren, ohne Nachbearbeitung
- Timbre- und Emotionstrennung — dieselbe Stimme kann auf Wunsch fröhlich, traurig oder wütend klingen
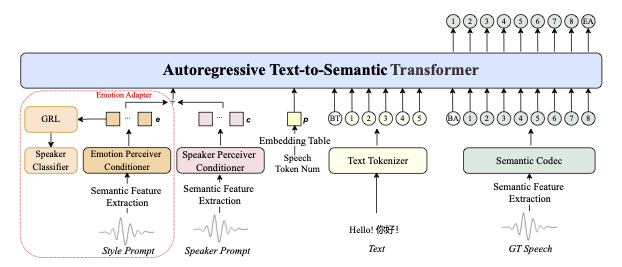
5 Gründe, auf IndexTTS2 zu achten
-
Kino-reifes Video-Dubbing
- Steuerbare Dauer jedes Wortes – perfekt fürs Dubbing
- Beispiel:
tts.infer(spk_audio_prompt='voice.wav', text="Точное время", output_path="dub.wav")
-
Emotionen unter Ihrer Kontrolle
- 8 Basisemotionen: Freude, Wut, Traurigkeit, Angst und mehr
- Kann über Audiobeispiel, Textbeschreibung oder numerischen Vektor angegeben werden
-
Zero-Shot-Learning
- Schon 3-5 Sekunden einer Stimmprobe reichen fürs Klonen
- Funktioniert sogar mit Stimmen, die nicht im Trainingsdatensatz enthalten sind
-
Professionelle Qualität
- Integrierter BigVGAN-Vocoder sorgt für sauberen Audio
- FP16-Unterstützung für Ausführung auf Consumer-GPUs
-
Direkt einsetzbare Werkzeuge
- Web-Interface für schnelles Testen
- Python-API für die Integration in Ihre Projekte
Wie es unter der Haube funktioniert
IndexTTS2 verwendet eine dreistufige Architektur:
-
Prompt-Analyse — separate Extraktion von:
- Timbre (aus Stimm-Prompt)
- Emotionen (aus Text oder Audio)
- Inhalt (aus Eingabetext)
-
Latente Repräsentation — mit Kontrolle über:
- Dauer über adaptives Schema
- Emotionen über GPT-ähnliches Modell
-
Sprachsynthese — unter Verwendung von:
- Modifiziertem autoregressivem Decoder
- Hochwertigem BigVGAN-Vocoder
Wo kann dies angewendet werden?
- Video-Dubbing — Lippen-Synchronisation
- Spiel-Vertonung — dynamische NPC-Dialoggenerierung
- Sprachassistenten — emotionale Antworten
- Hörbücher — verschiedene Stimmen und Intonationen
- Bildung — Vertonung von Lernmaterialien
Wie beginne ich?
Installation in 5 Schritten:
git clone https://github.com/index-tts/index-tts.git
cd index-tts
uv sync --all-extras
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
uv run webui.py
Oder ein einfaches Python-Skript:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(model_dir="checkpoints")
tts.infer(
spk_audio_prompt='voice.wav',
text="Привет, мир!",
output_path="output.wav",
emo_text="радостно"
)
Fazit: Lohnt es sich?
IndexTTS2 ist ein bedeutender Fortschritt in der Sprachsynthese. Wenn Sie:
- Videos mit präziser Synchronisation vertonen müssen
- Emotionale Voice-Bots erstellen möchten
- Mit generativer Audio experimentieren wollen
— dann lohnt es sich, dieses Tool kennenzulernen. Das Projekt entwickelt sich aktiv: Versionen 1.0, 1.5 und nun 2.0 wurden bereits veröffentlicht – mit grundlegenden Verbesserungen.
Testen Sie die Demo auf HuggingFace oder deployen Sie Ihre eigene Instanz — dies könnte genau das Tool sein, das Ihnen für Sprachsynthese-Projekte gefehlt hat.
Ähnliche Projekte