IndexTTS2: When Synthesized Speech Sounds Truly Natural
Imagine: you need to voice over a video where every word must precisely match the actor's lip movements. Or create a voice assistant that doesn't just mechanically read text, but conveys real emotions. With traditional TTS systems, this was almost impossible — until IndexTTS2 came along.
What is IndexTTS2?
IndexTTS2 is a next-generation open-source autoregressive speech synthesis model developed by a team from China. The project has already gathered nearly 10,000 stars on GitHub, and for good reason.
The main advantage? IndexTTS2 solves two key problems of modern TTS systems:
- Precise duration control — now you can synchronize speech with video without post-processing
- Timbre and emotion separation — the same voice can sound happy, sad, or angry of your choosing
5 reasons to pay attention to IndexTTS2
-
Cinema-quality video dubbing
- Controllable duration of each word is perfect for dubbing
- Example:
tts.infer(spk_audio_prompt='voice.wav', text="Точное время", output_path="dub.wav")
-
Emotions under your control
- 8 basic emotions: joy, anger, sadness, fear, and more
- Can be specified via audio example, text description, or numerical vector
-
Zero-shot learning
- Just 3-5 seconds of a voice sample is enough for cloning
- Works even with voices not in the training dataset
-
Professional quality
- Built-in BigVGAN vocoder ensures clean audio
- FP16 support for running on consumer GPUs
-
Ready-to-use tools
- Web interface for quick testing
- Python API for integration into your projects
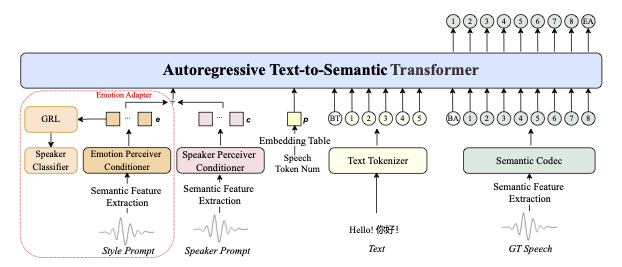
How it works under the hood
IndexTTS2 uses a three-stage architecture:
-
Prompt analysis — separate extraction of:
- Timbre (from voice prompt)
- Emotions (from text or audio)
- Content (from input text)
-
Latent representation generation — with control over:
- Duration via adaptive scheme
- Emotions via GPT-like model
-
Speech synthesis — using:
- Modified autoregressive decoder
- High-quality BigVGAN vocoder
Where can this be applied?
- Video dubbing — lip-sync synchronization
- Game voiceovers — dynamic NPC dialogue generation
- Voice assistants — emotional responses
- Audiobooks — different voices and intonations
- Education — narration of learning materials
How to get started?
Installation in 5 steps:
git clone https://github.com/index-tts/index-tts.git
cd index-tts
uv sync --all-extras
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
uv run webui.py
Or a simple Python script:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(model_dir="checkpoints")
tts.infer(
spk_audio_prompt='voice.wav',
text="Привет, мир!",
output_path="output.wav",
emo_text="радостно"
)
Conclusion: is it worth trying?
IndexTTS2 is a significant step forward in speech synthesis. If you need to:
- Voice over videos with precise synchronization
- Create emotional voice bots
- Experiment with generative audio
— this tool is worth learning. The project is actively developing: versions 1.0, 1.5, and now 2.0 have already been released with radical improvements.
Try the demo on HuggingFace or deploy your own copy — this might be exactly the tool you've been missing for speech synthesis projects.
Related projects