IndexTTS2: Wanneer Geproduceerde Spraak Echt Natuurlijk Klinkt
Stel je voor: je moet een video inspreken waarbij elk woord precies moet overeenkomen met de lipbewegingen van de acteur. Of maak een stemassistent die niet alleen mechanisch tekst voorleest, maar echte emoties overbrengt. Met traditionele TTS-systemen was dit bijna onmogelijk — tot IndexTTS2 kwam.
Wat is IndexTTS2?
IndexTTS2 is een next-generation open-source autoregressief spraaksynthesemodel ontwikkeld door een team uit China. Het project heeft inmiddels bijna 10.000 sterren verzameld op GitHub, en dat is niet voor niets.
Het belangrijkste voordeel? IndexTTS2 lost twee belangrijke problemen van moderne TTS-systemen op:
- Nauwkeurige duurcontrole — nu kun je spraak synchroniseren met video zonder nabewerking
- Timbrescheiding en emotiescheiding — dezelfde stem kan blij, verdrietig of boos klinken naar keuze
5 redenen om aandacht te besteden aan IndexTTS2
-
Filmkwaliteit videodubbing
- Controleerbare duur van elk woord is perfect voor dubbing
- Voorbeeld:
tts.infer(spk_audio_prompt='voice.wav', text="Точное время", output_path="dub.wav")
-
Emoties onder je controle
- 8 basismoties: vreugde, boosheid, verdriet, angst en meer
- Kan worden opgegeven via audiovoorbeeld, tekstbeschrijving of numerieke vector
-
Zero-shot learning
- Slechts 3-5 seconden van een stemvoorbeeld is voldoende voor klonen
- Werkt zelfs met stemmen die niet in de trainingsdataset zitten
-
Professionele kwaliteit
- Ingebouwde BigVGAN vocoder zorgt voor helder audio
- FP16-ondersteuning voor uitvoering op consumenten-GPU's
-
Gebruiksklare tools
- Webinterface voor snel testen
- Python API voor integratie in je projecten
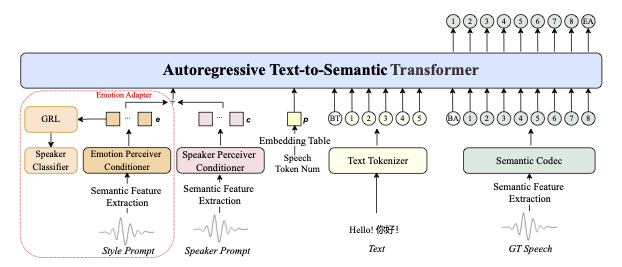
Hoe het werkt onder de motorkap
IndexTTS2 gebruikt een driedelige architectuur:
-
Prompt-analyse — afzonderlijke extractie van:
- Timbres (uit stemprompt)
- Emoties (uit tekst of audio)
- Inhoud (uit invoertekst)
-
Latente representatiegeneratie — met controle over:
- Duur via adaptief schema
- Emoties via GPT-achtig model
-
Spraaksynthese — met gebruik van:
- Aangepaste autoregressieve decoder
- Hoogwaardige BigVGAN vocoder
Waar kan dit worden toegepast?
- Videodubbing — lip-sync-synchronisatie
- Game-stemmen — dynamische NPC-dialooggeneratie
- Stemassistenten — emotionele reacties
- Audioboeken — verschillende stemmen en intonaties
- Onderwijs — narratie van leermateriaal
Hoe begin je?
Installatie in 5 stappen:
git clone https://github.com/index-tts/index-tts.git
cd index-tts
uv sync --all-extras
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
uv run webui.py
Of een eenvoudig Python-script:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(model_dir="checkpoints")
tts.infer(
spk_audio_prompt='voice.wav',
text="Привет, мир!",
output_path="output.wav",
emo_text="радостно"
)
Conclusie: is het de moeite waard om te proberen?
IndexTTS2 is een belangrijke stap voorwaarts in spraaksynthese. Als je nodig hebt:
- Video's inspreken met nauwkeurige synchronisatie
- Emotionele stem-bots maken
- Experimenteren met generatieve audio
— dit tool is de moeite waard om te leren. Het project ontwikkelt actief: versies 1.0, 1.5 en nu 2.0 zijn al uitgebracht met radicale verbeteringen.
Probeer de demo op HuggingFace of deploy je eigen exemplaar — dit zou precies het tool kunnen zijn dat je miste voor spraaksyntheseprojecten.
Gerelateerde projecten