IndexTTS2: Cuando el habla sintetizada suena verdaderamente natural
Imagina: necesitas poner voz a un video donde cada palabra debe coincidir exactamente con los movimientos labiales del actor. O crear un asistente de voz que no solo lea el texto mecánicamente, sino que transmita emociones reales. Con los sistemas TTS tradicionales, esto era casi imposible — hasta que llegó IndexTTS2.
¿Qué es IndexTTS2?
IndexTTS2 es un modelo de síntesis de voz autorregresivo de código abierto de nueva generación desarrollado por un equipo de China. El proyecto ya ha acumulado casi 10,000 estrellas en GitHub, y con razón.
¿La principal ventaja? IndexTTS2 resuelve dos problemas clave de los sistemas TTS modernos:
- Control preciso de duración — ahora puedes sincronizar el habla con el video sin posprocesamiento
- Separación de timbre y emoción — la misma voz puede sonar feliz, triste o enojada según tu elección
5 razones para prestar atención a IndexTTS2
-
Doblaje de video con calidad cinematográfica
- La duración controlable de cada palabra es perfecta para doblaje
- Ejemplo:
tts.infer(spk_audio_prompt='voice.wav', text="Точное время", output_path="dub.wav")
-
Emociones bajo tu control
- 8 emociones básicas: alegría, enojo, tristeza, miedo y más
- Se puede especificar mediante ejemplo de audio, descripción de texto o vector numérico
-
Aprendizaje zero-shot
- Solo 3-5 segundos de una muestra de voz son suficientes para clonación
- Funciona incluso con voces que no están en el conjunto de datos de entrenamiento
-
Calidad profesional
- El vocoder integrado BigVGAN garantiza audio limpio
- Soporte FP16 para ejecutar en GPUs de consumo
-
Herramientas listas para usar
- Interfaz web para pruebas rápidas
- API de Python para integración en tus proyectos
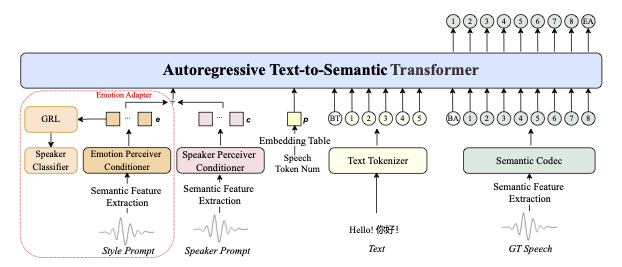
Cómo funciona internamente
IndexTTS2 utiliza una arquitectura de tres etapas:
-
Análisis de prompt — extracción separada de:
- Timbre (del prompt de voz)
- Emociones (del texto o audio)
- Contenido (del texto de entrada)
-
Generación de representación latente — con control sobre:
- Duración mediante esquema adaptativo
- Emociones mediante modelo tipo GPT
-
Síntesis de voz — usando:
- Decodificador autorregresivo modificado
- Vocoder BigVGAN de alta calidad
¿Dónde se puede aplicar esto?
- Doblaje de video — sincronización de labios
- Voces de juegos — generación de diálogo dinámico de NPCs
- Asistentes de voz — respuestas emocionales
- Audiolibros — diferentes voces e inflexiones
- Educación — narración de materiales de aprendizaje
¿Cómo comenzar?
Instalación en 5 pasos:
git clone https://github.com/index-tts/index-tts.git
cd index-tts
uv sync --all-extras
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
uv run webui.py
O un script simple de Python:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(model_dir="checkpoints")
tts.infer(
spk_audio_prompt='voice.wav',
text="Привет, мир!",
output_path="output.wav",
emo_text="радостно"
)
Conclusión: ¿vale la pena probarlo?
IndexTTS2 es un paso significativo hacia adelante en la síntesis de voz. Si necesitas:
- Poner voz a videos con sincronización precisa
- Crear bots de voz emocionales
- Experimentar con audio generativo
— esta herramienta vale la pena aprenderla. El proyecto se está desarrollando activamente: las versiones 1.0, 1.5 y ahora 2.0 ya han sido lanzadas con mejoras radicales.
Prueba la demo en HuggingFace o despliega tu propia copia — esto podría ser exactamente la herramienta que te faltaba para proyectos de síntesis de voz.
Proyectos relacionados