IndexTTS2 : quand la synthèse vocale sonne vraiment naturelle
Imaginez : vous devez enregistrer le commentaire d'une vidéo où chaque mot doit correspondre précisément aux mouvements labiaux de l'acteur. Ou créer un assistant vocal qui ne se contente pas de lire mécaniquement le texte, mais transmet de vraies émotions. Avec les systèmes TTS traditionnels, c'était presque impossible — jusqu'à l'arrivée d'IndexTTS2.
Qu'est-ce qu'IndexTTS2 ?
IndexTTS2 est un modèle de synthèse vocale autorégressif open source de nouvelle génération développé par une équipe de Chine. Le projet a déjà recueilli près de 10 000 étoiles sur GitHub, et ce n'est pas pour rien.
Le principal avantage ? IndexTTS2 résout deux problèmes clés des systèmes TTS modernes :
- Contrôle précis de la durée — vous pouvez désormais synchroniser la parole avec la vidéo sans post-traitement
- Séparation du timbre et des émotions — la même voix peut sonner joyeuse, triste ou en colère, à votre choix
5 raisons de s'intéresser à IndexTTS2
-
Doublage vidéo de qualité cinématographique
- La durée contrôlable de chaque mot est parfaite pour le doublage
- Exemple :
tts.infer(spk_audio_prompt='voice.wav', text="Точное время", output_path="dub.wav")
-
Les émotions sous votre contrôle
- 8 émotions de base : joie, colère, tristesse, peur, et plus encore
- Peut être spécifié via un exemple audio, une description textuelle ou un vecteur numérique
-
Apprentissage zero-shot
- 3 à 5 secondes d'un échantillon vocal suffisent pour le clonage
- Fonctionne même avec des voix absentes de l'ensemble de données d'entraînement
-
Qualité professionnelle
- Le vocodeur intégré BigVGAN garantit un audio cristallin
- Support FP16 pour fonctionner sur des GPU grand public
-
Outils prêts à l'emploi
- Interface web pour des tests rapides
- API Python pour l'intégration dans vos projets
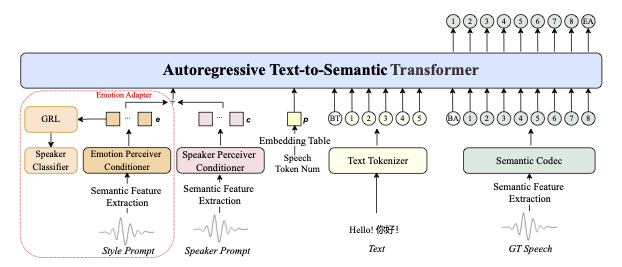
Comment ça fonctionne sous le capot
IndexTTS2 utilise une architecture en trois étapes :
-
Analyse des invites — extraction séparée de :
- Timbre (à partir de l'invite vocale)
- Émotions (à partir du texte ou de l'audio)
- Contenu (à partir du texte d'entrée)
-
Génération de représentation latente — avec contrôle sur :
- Durée via schéma adaptatif
- Émotions via modèle de type GPT
-
Synthèse vocale — en utilisant :
- Décodeur autorégressif modifié
- Vocodeur haute qualité BigVGAN
Où peut-on l'appliquer ?
- Doublage vidéo — synchronisation labiale
- Doublages de jeux — génération de dialogues NPC dynamiques
- Assistants vocaux — réponses émotionnelles
- Livres audio — différentes voix et intonations
- Éducation — narration de supports d'apprentissage
Comment commencer ?
Installation en 5 étapes :
git clone https://github.com/index-tts/index-tts.git
cd index-tts
uv sync --all-extras
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
uv run webui.py
Ou un simple script Python :
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(model_dir="checkpoints")
tts.infer(
spk_audio_prompt='voice.wav',
text="Привет, мир!",
output_path="output.wav",
emo_text="радостно"
)
Conclusion : vaut-il la peine d'essayer ?
IndexTTS2 est un pas en avant significatif dans la synthèse vocale. Si vous avez besoin de :
- Doubler des vidéos avec une synchronisation précise
- Créer des bots vocaux émotionnels
- Experimenter avec l'audio génératif
— cet outil mérite d'être appris. Le projet est en développement actif : les versions 1.0, 1.5 et maintenant 2.0 ont déjà été publiées avec des améliorations radicales.
Essayez la démo sur HuggingFace ou déployez votre propre instance — ce pourrait être exactement l'outil qu'il vous manque pour vos projets de synthèse vocale.
Projets similaires