IndexTTS2: Quando la Sintesi Vocale Suona Davvero Naturale
Immagina: devi creare il voiceover di un video in cui ogni parola deve combaciare perfettamente con i movimenti labiali dell'attore. Oppure devi realizzare un assistente vocale che non si limiti a leggere meccanicamente il testo, ma trasmetta vere emozioni. Con i sistemi TTS tradizionali, questo era quasi impossibile — fino all'arrivo di IndexTTS2.
Cos'è IndexTTS2?
IndexTTS2 è un modello open-source di nuova generazione per la sintesi vocale autoregressiva, sviluppato da un team cinese. Il progetto ha già raccolto quasi 10.000 stelle su GitHub, e non a caso.
Il principale vantaggio? IndexTTS2 risolve due problemi chiave degli attuali sistemi TTS:
- Controllo preciso della durata — ora puoi sincronizzare il parlato con il video senza post-elaborazione
- Separazione di timbro ed emozioni — la stessa voce può suonare felice, triste o arrabbiata a tua scelta
5 motivi per prestare attenzione a IndexTTS2
-
Doppiaggio video di qualità cinematografica
- La durata controllabile di ogni parola è perfetta per il doppiaggio
- Esempio:
tts.infer(spk_audio_prompt='voice.wav', text="Точное время", output_path="dub.wav")
-
Emozioni sotto il tuo controllo
- 8 emozioni base: gioia, rabbia, tristezza, paura e altro
- Possono essere specificate tramite esempio audio, descrizione testuale o vettore numerico
-
Apprendimento zero-shot
- Bastano 3-5 secondi di un campione vocale per il cloning
- Funziona anche con voci non presenti nel dataset di training
-
Qualità professionale
- Il vocoder integrato BigVGAN garantisce audio pulito
- Supporto FP16 per l'esecuzione su GPU consumer
-
Strumenti pronti all'uso
- Interfaccia web per test rapidi
- API Python per l'integrazione nei tuoi progetti
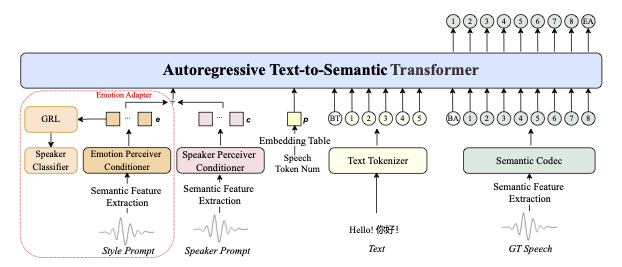
Come funziona sotto il cofano
IndexTTS2 utilizza un'architettura a tre stadi:
-
Analisi del prompt — estrazione separata di:
- Timbro (dal prompt vocale)
- Emozioni (dal testo o dall'audio)
- Contenuto (dal testo di input)
-
Generazione della rappresentazione latente — con controllo su:
- Durata tramite schema adattivo
- Emozioni tramite modello tipo GPT
-
Sintesi vocale — utilizzando:
- Decoder autoregressivo modificato
- Vocoder BigVGAN di alta qualità
Dove può essere applicato?
- Doppiaggio video — sincronizzazione labiale
- Voiceover per videogiochi — generazione dinamica di dialoghi NPC
- Assistenti vocali — risposte emotive
- Audiolibri — voci e intonazioni diverse
- Istruzione — narrazione di materiali didattici
Come iniziare?
Installazione in 5 passaggi:
git clone https://github.com/index-tts/index-tts.git
cd index-tts
uv sync --all-extras
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
uv run webui.py
Oppure un semplice script Python:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(model_dir="checkpoints")
tts.infer(
spk_audio_prompt='voice.wav',
text="Привет, мир!",
output_path="output.wav",
emo_text="радостно"
)
Conclusione: vale la pena provarlo?
IndexTTS2 rappresenta un passo significativo in avanti nella sintesi vocale. Se hai bisogno di:
- Creare voiceover di video con sincronizzazione precisa
- Creare voice bot emotivi
- Sperimentare con l'audio generativo
— questo strumento merita di essere imparato. Il progetto è in fase di sviluppo attivo: le versioni 1.0, 1.5 e ora 2.0 sono già state rilasciate con miglioramenti radicali.
Prova la demo su HuggingFace oppure esegui il deploy della tua copia — potrebbe essere esattamente lo strumento che ti mancava per i progetti di sintesi vocale.
Progetti correlati