IndexTTS2: Quando a Fala Sintetizada Soa Verdadeiramente Natural
Imagine: você precisa fazer a narração de um vídeo onde cada palavra deve corresponder precisamente aos movimentos labiais do ator. Ou criar um assistente de voz que não apenas lê mecanicamente o texto, mas transmite emoções reais. Com sistemas TTS tradicionais, isso era quase impossível — até o IndexTTS2 aparecer.
O que é o IndexTTS2?
IndexTTS2 é um modelo de síntese de fala autorregressivo open-source de próxima geração desenvolvido por uma equipe da China. O projeto já reuniu quase 10.000 estrelas no GitHub, e por bons motivos.
A principal vantagem? O IndexTTS2 resolve dois problemas-chave dos sistemas TTS modernos:
- Controle preciso de duração — agora você pode sincronizar a fala com o vídeo sem pós-processamento
- Separação de timbre e emoção — a mesma voz pode soar feliz, triste ou irritada, conforme sua escolha
5 motivos para prestar atenção ao IndexTTS2
-
Dublagem de vídeos com qualidade cinematográfica
- A duração controlável de cada palavra é perfeita para dublagem
- Exemplo:
tts.infer(spk_audio_prompt='voice.wav', text="Точное время", output_path="dub.wav")
-
Emoções sob seu controle
- 8 emoções básicas: alegria, raiva, tristeza, medo e mais
- Podem ser especificadas via exemplo de áudio, descrição de texto ou vetor numérico
-
Aprendizado zero-shot
- Basta 3-5 segundos de uma amostra de voz para clonagem
- Funciona mesmo com vozes que não estão no conjunto de treinamento
-
Qualidade profissional
- Vocoder BigVGAN integrado garante áudio limpo
- Suporte a FP16 para execução em GPUs de usuário
-
Ferramentas prontas para uso
- Interface web para testes rápidos
- API Python para integração em seus projetos
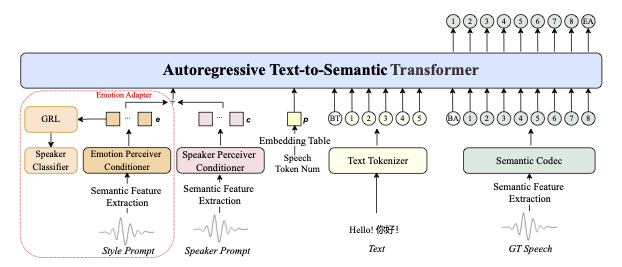
Como funciona nos bastidores
O IndexTTS2 usa uma arquitetura de três estágios:
-
Análise do prompt — extração separada de:
- Timbre (do prompt de voz)
- Emoções (do texto ou áudio)
- Conteúdo (do texto de entrada)
-
Geração de representação latente — com controle sobre:
- Duração via esquema adaptativo
- Emoções via modelo tipo GPT
-
Síntese de fala — usando:
- Decodificador autorregressivo modificado
- Vocoder BigVGAN de alta qualidade
Onde isso pode ser aplicado?
- Dublagem de vídeos — sincronização de sincronia labial
- Narração de jogos — geração dinâmica de diálogos de NPCs
- Assistentes de voz — respostas emocionais
- Audiolivros — diferentes vozes e entonações
- Educação — narração de materiais de aprendizagem
Como começar?
Instalação em 5 passos:
git clone https://github.com/index-tts/index-tts.git
cd index-tts
uv sync --all-extras
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
uv run webui.py
Ou um script Python simples:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(model_dir="checkpoints")
tts.infer(
spk_audio_prompt='voice.wav',
text="Привет, мир!",
output_path="output.wav",
emo_text="радостно"
)
Conclusão: vale a pena experimentar?
O IndexTTS2 é um passo significativo na síntese de fala. Se você precisa:
- Narrar vídeos com sincronização precisa
- Criar bots de voz emocionais
- Experimentar com áudio generativo
— esta ferramenta vale a pena aprender. O projeto está em desenvolvimento ativo: as versões 1.0, 1.5 e agora 2.0 já foram lançadas com melhorias radicais.
Experimente o demo no HuggingFace ou faça deploy da sua própria cópia — isso pode ser exatamente a ferramenta que você estava faltando para projetos de síntese de fala.
Projetos relacionados