IndexTTS2:合成音声が真に自然に聞こえるとき
21,665 スター
想像してみてください:俳優の唇の動きに各言葉が正確に一致する必要がある動画の吹き替え。或者は、テキストを機械的に読み上げるだけでなく、本当の感情を伝える音声アシスタントを作成したいとします。従来のTTSシステムでは、これはほぼ不可能でした—IndexTTS2が登場するまで。
IndexTTS2とは?
IndexTTS2は、中国のチームによって開発された次世代オープンソース自己回帰型音声合成モデルです。このプロジェクトは既にGitHubで10,000に近いスターを集めており、 それには理由があります。
主な利点は?IndexTTS2は現代のTTSシステムにおける2つの主要な問題を解決します:
- 精密なduration制御 — これで事後処理なしで音声と動画を同期できます
- 音色と感情の分離 — 同じ音声を喜び、悲しみ、怒りなど自由に表現できます
IndexTTS2注目すべき5つの理由
-
シネマ品質の動画吹き替え
- 各単語のdurationを制御できるため、吹き替えに最適
- 例:
tts.infer(spk_audio_prompt='voice.wav', text="Точное время", output_path="dub.wav")
-
感情を自在にコントロール
- 8つの基本感情:喜び、怒り、悲しみ、恐怖など
- 音声例、テキスト説明、数値ベクトルで指定可能
-
ゼロショット学習
- 音声サンプル3〜5秒でクローニング可能
- 学習データセットにない音声でも動作
-
プロフェッショナルな品質
- 組み込みのBigVGANボコーダーがクリーンな音声を保証
- FP16サポートでコンシューマーGPUでも動作
-
すぐ使えるツール
- クイックテスト用のWebインターフェース
- プロジェクト統合用のPython API
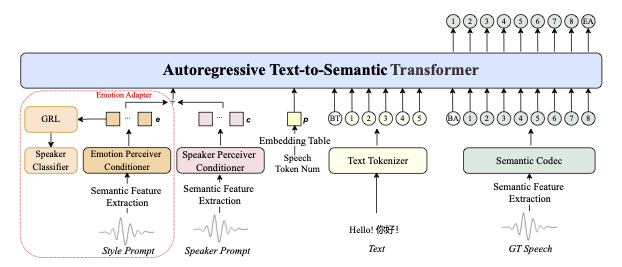
内部動作の仕組み
IndexTTS2は3段階アーキテクチャを使用しています:
-
プロンプト分析 — 以下の要素を分離して抽出:
- 音色(音声プロンプトから)
- 感情(テキストまたは音声から)
- 内容(入力テキストから)
-
潜在表現の生成 — 以下の制御が可能:
- 適応スキームによるduration
- GPTライクなモデルによる感情
-
音声合成 — 以下の技術を使用:
- 改良された自己回帰デコーダー
- 高品質なBigVGANボコーダー
適用可能な分野
- 動画吹き替え — リップシンク同期
- ゲームボイスオーバー — 動的なNPC対話生成
- 音声アシスタント — 感情的な応答
- オーディオブック — 異なる音声とイントネーション
- 教育 — 学習教材のナレーション
始め方
5ステップでのインストール:
git clone https://github.com/index-tts/index-tts.git
cd index-tts
uv sync --all-extras
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
uv run webui.py
またはシンプルなPythonスクリプト:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(model_dir="checkpoints")
tts.infer(
spk_audio_prompt='voice.wav',
text="Привет, мир!",
output_path="output.wav",
emo_text="радостно"
)
結論:試す価値はあるか?
IndexTTS2は音声合成において大きな前進です。以下が必要な場合:
- 精密な同期が必要な動画の吹き替え
- 感情的な音声ボットの作成
- 生成オーディオの実験
— このツールは学ぶ価値があります。このプロジェクトは積極的に開発されています:バージョン1.0、1.5、そして現在の2.0がラディカルな改善と共に既にリリースされています。
HuggingFaceでデモを試すか、自分のコピーをデプロイしてください—これは音声合成プロジェクトに欠けていたツールかもしれません。
関連プロジェクト