IndexTTS2: kiedy syntetyzowana mowa brzmi naprawdę naturalnie
Wyobraź sobie: musisz nagrać lektora do filmu, w którym każde słowo musi idealnie pasować do ruchu warg aktora. Albo stworzyć asystenta głosowego, który nie tylko mechanicznie odczytuje tekst, ale przekazuje prawdziwe emocje. W tradycyjnych systemach TTS było to prawie niemożliwe — dopóki nie pojawił się IndexTTS2.
Czym jest IndexTTS2?
IndexTTS2 to next-generation model syntezy mowy open-source typu autoregresyjnego, opracowany przez zespół z Chin. Projekt zdobył już prawie 10 000 gwiazdek na GitHubie, i to z dobrych powodów.
Główna zaleta? IndexTTS2 rozwiązuje dwa kluczowe problemy nowoczesnych systemów TTS:
- Precyzyjna kontrola czasu trwania — teraz możesz synchronizować mowę z wideo bez post-processingu
- Separacja barwy głosu i emocji — ten sam głos może brzmieć radośnie, smutno lub gniewnie — według Twojego wyboru
5 powodów, by zwrócić uwagę na IndexTTS2
-
Dubbing filmowy jakości kinowej
- Kontrolowany czas trwania każdego słowa idealnie nadaje się do dubbingu
- Przykład:
tts.infer(spk_audio_prompt='voice.wav', text="Точное время", output_path="dub.wav")
-
Emocje pod Twoją kontrolą
- 8 podstawowych emocji: radość, gniew, smutek, strach i więcej
- Można je określić za pomocą przykładu audio, opisu tekstowego lub wektora numerycznego
-
Uczenie typu zero-shot
- Wystarczy 3-5 sekund próbki głosu do klonowania
- Działa nawet z głosami spoza zbioru treningowego
-
Jakość profesjonalna
- Wbudowany vocoder BigVGAN zapewnia czysty dźwięk
- Obsługa FP16 do uruchamiania na konsumenckich GPU
-
Narzędzia gotowe do użycia
- Interfejs webowy do szybkiego testowania
- Python API do integracji z Twoimi projektami
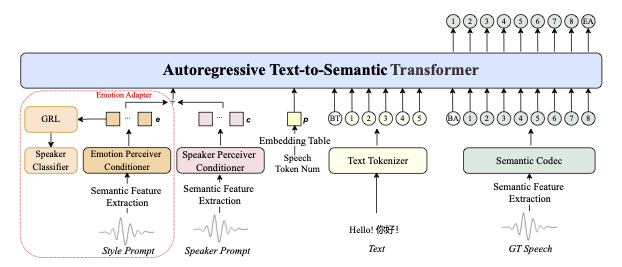
Jak to działa pod maską
IndexTTS2 wykorzystuje trójstopniową architekturę:
-
Analiza promptu — oddzielne wyodrębnienie:
- Barwy głosu (z promptu głosowego)
- Emocji (z tekstu lub audio)
- Treści (z tekstu wejściowego)
-
Generowanie reprezentacji latentnej — z kontrolą:
- Czasu trwania poprzez adaptacyjny schemat
- Emocji poprzez model typu GPT
-
Synteza mowy — z użyciem:
- Zmodyfikowanego dekodera autoregresyjnego
- Wysokiej jakości vocodera BigVGAN
Gdzie można to zastosować?
- Dubbing wideo — synchronizacja z ruchem warg
- Lektory w grach — dynamiczna generacja dialogów NPC
- Asystenci głosowi — emocjonalne odpowiedzi
- Audiobooki — różne głosy i intonacje
- Edukacja — narracja materiałów edukacyjnych
Jak zacząć?
Instalacja w 5 krokach:
git clone https://github.com/index-tts/index-tts.git
cd index-tts
uv sync --all-extras
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
uv run webui.py
Albo prosty skrypt Python:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(model_dir="checkpoints")
tts.infer(
spk_audio_prompt='voice.wav',
text="Привет, мир!",
output_path="output.wav",
emo_text="радостно"
)
Podsumowanie: czy warto wypróbować?
IndexTTS2 to istotny krok naprzód w syntezie mowy. Jeśli potrzebujesz:
- Lektora do filmów z precyzyjną synchronizacją
- Tworzyć emocjonalne boty głosowe
- Eksperymentować z generatywnym audio
— ten tool jest warty poznania. Projekt aktywnie się rozwija: wydano już wersje 1.0, 1.5 i teraz 2.0 z radykalnymi usprawnieniami.
Wypróbuj demo na HuggingFace lub wdrażaj własną instancję — to może być dokładnie ten tool, którego Ci brakowało w projektach syntezy mowy.
Powiązane projekty