Cómo funcionan los gigantes de redes neuronales bajo el capó
Cuando intenté por primera vez entender cómo se entrenan modelos como Llama o DeepSeek en miles de GPUs, me topé con un muro. Los tutoriales de PyTorch explican cómo entrenar un clasificador de gatos, pero guardan silencio sobre cómo hacer que diez mil GPUs se comuniquen entre sí sin retrasos. El proyecto AIInfra es exactamente el recurso que los desarrolladores necesitan cuando deciden mirar bajo el capó de los modelos de lenguaje grandes (LLMs).
¿Qué es esta bestia?
AIInfra (AI Infrastructure) es un enorme repositorio educativo que desglosa paso a paso cómo funciona la infraestructura de redes neuronales. Su autor, conocido en la comunidad como ZOMI, ha reunido todo: desde el diseño físico de servidores y switches de red hasta algoritmos de entrenamiento distribuido y estrategias de inferencia.
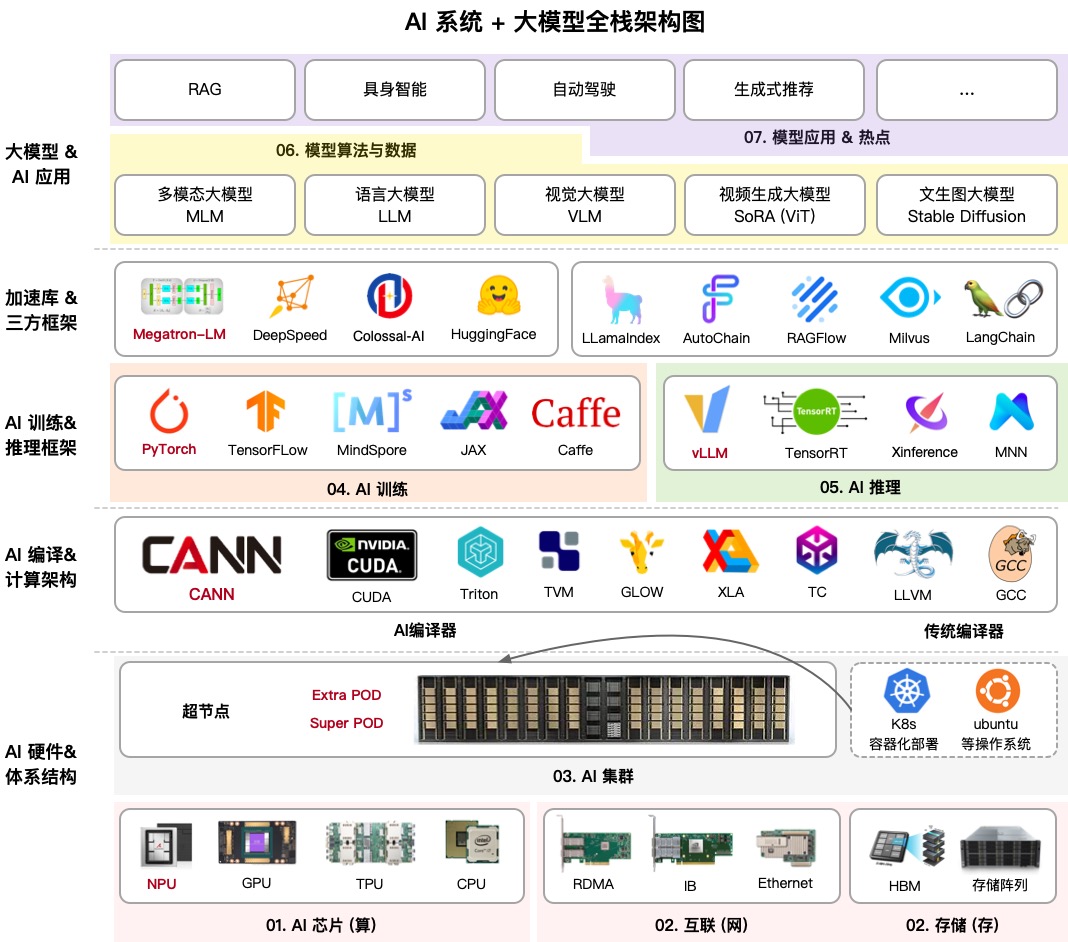
Si pensabas que se trataba solo de escribir código Python, este proyecto te sorprenderá. Cubre desde el enfriamiento de racks de servidores en centros de datos hasta topologías de red InfiniBand, y por qué el Ethernet convencional no puede manejar el entrenamiento de LLMs modernos. Este es un mapa de conocimiento completo para quienes quieran llamarse ingenieros de ML o arquitectos de sistemas en la era de la IA.
Para quién está escrito esta guía
El proyecto será útil para quienes se sientan limitados dentro de los límites de simplemente usar las APIs de OpenAI o Anthropic. Si necesitas:
- Entender por qué tu modelo se entrena lentamente aunque hayas comprado GPUs potentes.
- Averiguar cómo funcionan la paralelización de datos, tensores y pipelines.
- Configurar tu propio clúster de Kubernetes para cargas de trabajo de redes neuronales.
Curiosamente, el autor no solo proporciona teoría sino que también incluye notebooks de Jupyter y diapositivas. Parte del contenido está en chino, pero el código y los términos en inglés en los diagramas son intuitivos, y los traductores modernos manejan fácilmente el resto.
Cinco niveles de inmersión en AIInfra
El repositorio está organizado en módulos lógicos. He destacado los que parecieron más útiles para la práctica.
1. Hardware y clústeres
Aquí obtienes los fundamentos: cómo están estructurados los nodos de servidor, cómo funciona el enfriamiento y por qué las GPUs/NPUs se comportan de manera diferente. La sección sobre clústeres de 10,000 tarjetas es especialmente útil. En mi práctica, rara vez necesito trabajar a esa escala, pero entender cómo se distribuyen los recursos allí ayuda a optimizar mejor incluso configuraciones más pequeñas.
2. Comunicaciones y almacenamiento
Los modelos masivos no se pueden enviar simplemente por la red. AIInfra explica a fondo bibliotecas de comunicación colectiva como NCCL (de NVIDIA) y HCCL (de Huawei). Si alguna vez has visto el error NCCL TIMEOUT, esta sección te ayudará a entender exactamente dónde falló en la pila de red.
3. Entrenamiento distribuido
Esta es la "carne" del proyecto. El autor desmenuza PyTorch DDP (Distributed Data Parallel) y DeepSpeed hasta los huesos. Incluso hay ejemplos prácticos:
# Пример из материалов: создание своего DDP с нуля
# Помогает понять, что под капотом у стандартных библиотек
import torch.distributed as dist
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# Дальше идет логика распределения градиентов
Aquí también explican la tecnología ZeRO (Zero Redundancy Optimizer), que permite entrenar modelos que no caben en la memoria de una sola GPU mediante la división de estados del optimizador.
4. Arquitecturas de modelos: Transformer y MoE
En lugar de simplemente decir "usa Attention", el proyecto muestra cómo implementar sus variaciones (MHA, GQA, MLA) y cómo están estructurados los modelos dispersos (Mixture of Experts). Esto último es críticamente importante ahora, ya que casi todos los modelos de código abierto más importantes están construidos sobre este principio.
5. Inferencia y optimización
El entrenamiento es solo la mitad de la batalla. También necesitas que el modelo responda rápidamente. AIInfra cubre KV-caching, cuantización y destilación. Estos son los trucos exactos que te permiten ejecutar un modelo potente en hardware doméstico o instancias de nube económicas.
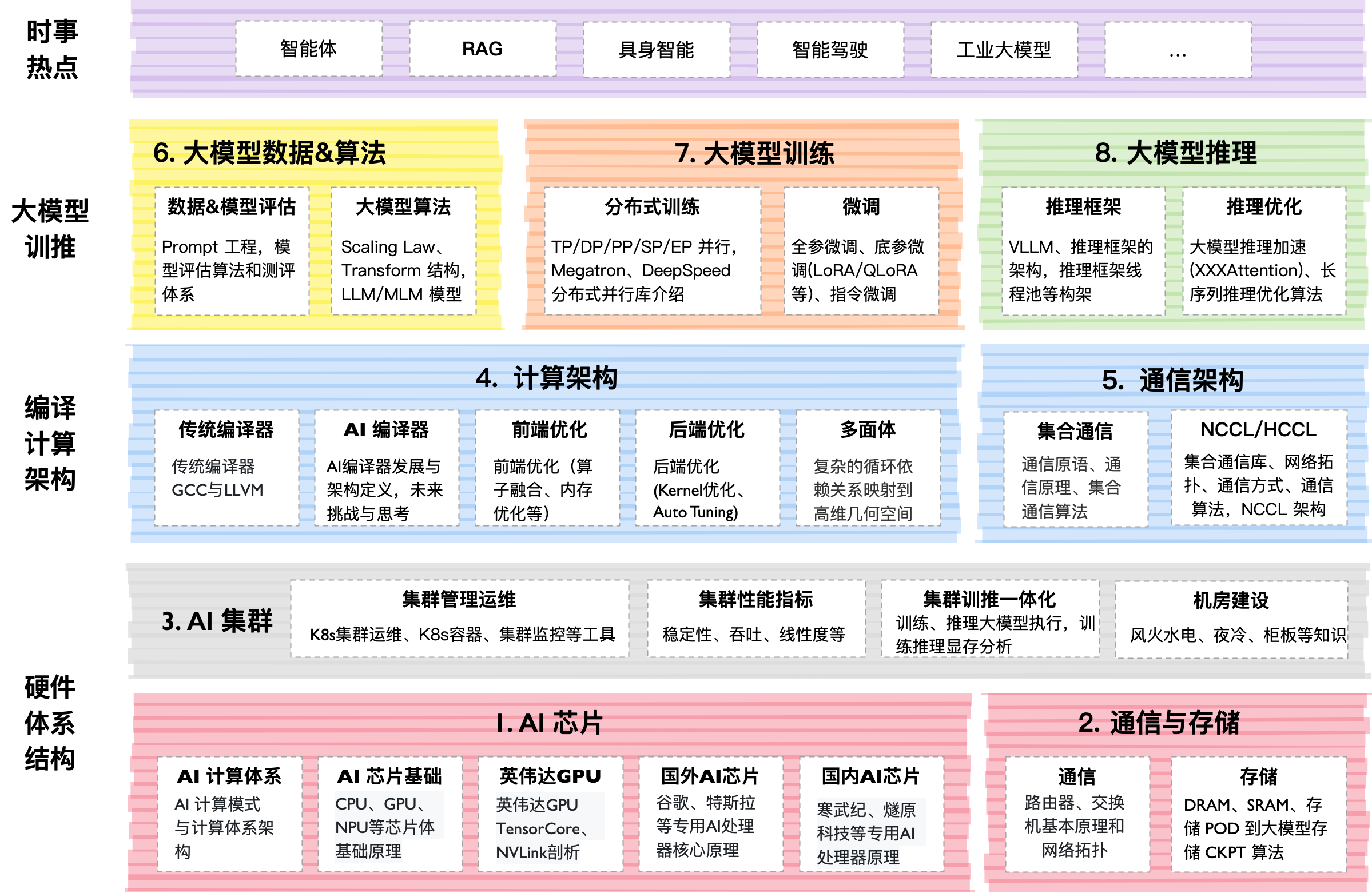
Interior técnico
El proyecto vive en formato de "libro vivo". El contenido principal está organizado en directorios por números (00–07). Dentro de cada uno hay archivos Markdown con explicaciones, diapositivas en PDF y notebooks de Jupyter.
Lo que me llamó la atención:
- Práctica: Hay código para implementar Flash Attention desde cero.
- Profundidad: Cobertura de las Leyes de Escala (Scaling Laws) — las leyes matemáticas que predicen cuánto más inteligente se volverá un modelo si le das más datos y GPUs.
- Escala: Todo el repositorio pesa aproximadamente 10 GB debido a la abundancia de gráficos y diagramas de alta resolución. El autor incluso recomienda descargar solo las partes necesarias a través de Releases.
Por qué deberías aprender esto
El mundo del ML se está alejando rápidamente de "solo entrenar" hacia sistemas de ingeniería complejos. Hoy, lo que se demanda no es alguien que sepa cómo llamar a model.fit(), sino alguien que entienda cómo pasar una GPU a un contenedor, configurar el monitoreo de recursos en K8s y optimizar el consumo de memoria mediante gradient checkpointing.
AIInfra es un boleto gratuito a este club exclusivo de ingenieros de sistemas. Incluso si no planeas construir tu propio ChatGPT, el conocimiento de arquitectura de memoria y protocolos de red te colocará muy por encima de cualquier científico de datos ordinario.
Por dónde empezar
Si decides sumergirte, no intentes leer todo de una vez. Recomiendo este camino:
- Echa un vistazo a la sección
04Trainpara entender la magia de la paralelización. - Descarga el notebook de
Transformeren la sección06AlgoDatae intenta ejecutarlo localmente. - Mira las diapositivas sobre inferencia en
05Infer— esta es la base para cualquier desarrollador backend que trabaje con IA.
El proyecto se actualiza constantemente, y aunque pueda parecer caótico debido a la mezcla de idiomas, es el agregador de conocimiento más completo sobre infraestructura de IA disponible hoy en día. ¿Vale la pena estudiarlo? Absolutamente, si planeas permanecer en la industria más allá del actual hype.
Proyectos relacionados