Hoe neurale netwerkgiganten onder de motorkap werken
Toen ik voor het eerst probeerde te begrijpen hoe modellen zoals Llama of DeepSeek worden getraind op duizenden GPU's, liep ik tegen een muur aan. PyTorch-tutorials leggen uit hoe je een kattenclassifier traint, maar ze zwijgen over hoe je tienduizend GPU's met elkaar laat communiceren zonder vertragingen. Het AIInfra-project is precies de bron die ontwikkelaars nodig hebben wanneer ze besluiten onder de motorkap van grote taalmodellen (LLM's) te kijken.
Wat is dit beest
AIInfra (AI Infrastructure) is een enorme educatieve repository die stap voor stap uitlegt hoe neurale netwerkinfrastructuur werkt. De auteur, bekend in de community als ZOMI, heeft alles samengebracht: van het fysieke ontwerp van servers en netwerkswitches tot gedistribueerde trainingsalgoritmen en inferentiestrategieën.
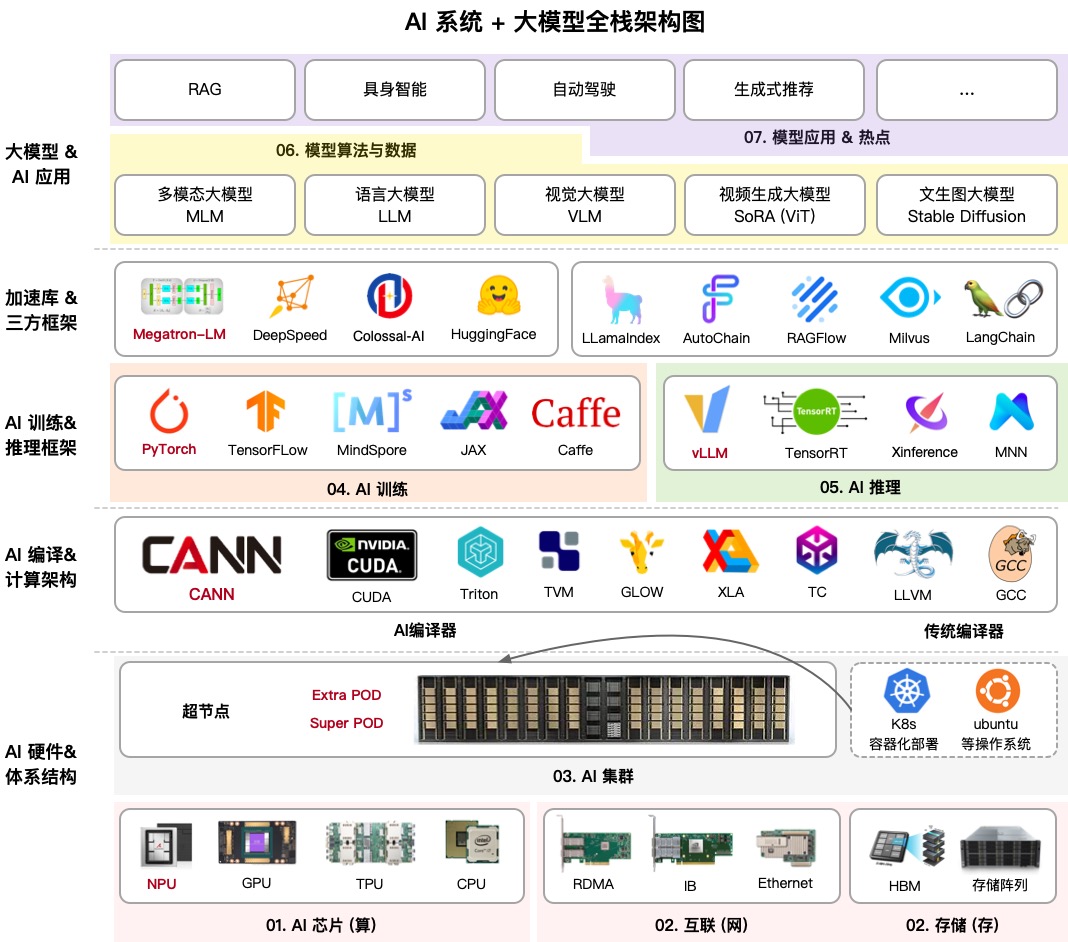
Als je dacht dat het allemaal om het schrijven van Python-code ging, zal dit project je verrassen. Het behandelt het koelen van serverracks in datacenters, InfiniBand-netwerktopologieën, en waarom gewone Ethernet niet kan omgaan met het trainen van moderne LLM's. Dit is een complete kenniskaart voor degenen die zich ML-engineer of systeemarchitect in het AI-tijdperk willen noemen.
Voor wie deze gids is
Het project is nuttig voor degenen die zich bekneld voelen binnen de grenzen van simpelweg het gebruiken van OpenAI- of Anthropic-API's. Als je nodig hebt:
- Te begrijpen waarom je model langzaam traint, ook al heb je krachtige GPU's gekocht.
- Uit te zoeken hoe data-, tensor- en pipeline-parallellisme werken.
- Je eigen Kubernetes-cluster op te zetten voor neurale netwerkworkloads.
Interessant is dat de auteur niet alleen theorie biedt, maar ook Jupyter-notebooks en slides bevat. Sommige inhoud is in het Chinees, maar de code en Engelse termen in diagrammen zijn intuïtief, en moderne vertalers verwerken de rest gemakkelijk.
Vijf niveaus van duiken in AIInfra
De repository is opgedeeld in logische modules. Ik heb degenen uitgelicht die het meest nuttig leken voor de praktijk.
1. Hardware en Clusters
Hier krijg je de basis: hoe servernodes zijn gestructureerd, hoe koeling werkt, en waarom GPU's/NPU's zich anders gedragen. De sectie over clusters met 10.000 kaarten is bijzonder nuttig. In mijn praktijk hoef ik zelden op zulke schaal te werken, maar begrijpen hoe resources daar worden verdeeld helpt zelfs kleinere opstellingen beter te optimaliseren.
2. Communicatie en Opslag
Massieve modellen kunnen niet zomaar over het netwerk worden verzonden. AIInfra legt collectieve communicatiebibliotheken grondig uit zoals NCCL (van NVIDIA) en HCCL (van Huawei). Als je ooit fout NCCL TIMEOUT hebt gezien, zal deze sectie je helpen precies te begrijpen waar in de netwerkstack dingen misgingen.
3. Gedistribueerd Trainen
Dit is het "hart" van het project. De auteur ontleedt PyTorch DDP (Distributed Data Parallel) en DeepSpeed tot op het bot. Er zijn zelfs praktische voorbeelden:
# Пример из материалов: создание своего DDP с нуля
# Помогает понять, что под капотом у стандартных библиотек
import torch.distributed as dist
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# Дальше идет логика распределения градиентов
Hier leggen ze ook ZeRO (Zero Redundancy Optimizer)-technologie uit, die het mogelijk maakt om modellen te trainen die niet in het geheugen van één GPU passen door optimizer-staten te splitsen.
4. Modelarchitecturen: Transformer en MoE
In plaats van simpelweg te zeggen "gebruik Attention," laat het project zien hoe je de variaties ervan implementeert (MHA, GQA, MLA) en hoe sparse modellen (Mixture of Experts) zijn gestructureerd. Dit laatste is nu cruciaal belangrijk, aangezien bijna alle top open-source modellen op dit principe zijn gebouwd.
5. Inferentie en Optimalisatie
Trainen is slechts de helft van de strijd. Je hebt ook nodig dat het model snel reageert. AIInfra behandelt KV-caching, kwantisatie en distillatie. Dit zijn precies de trucs waarmee je een krachtig model kunt draaien op thuishardware of goedkope cloud-instanties.
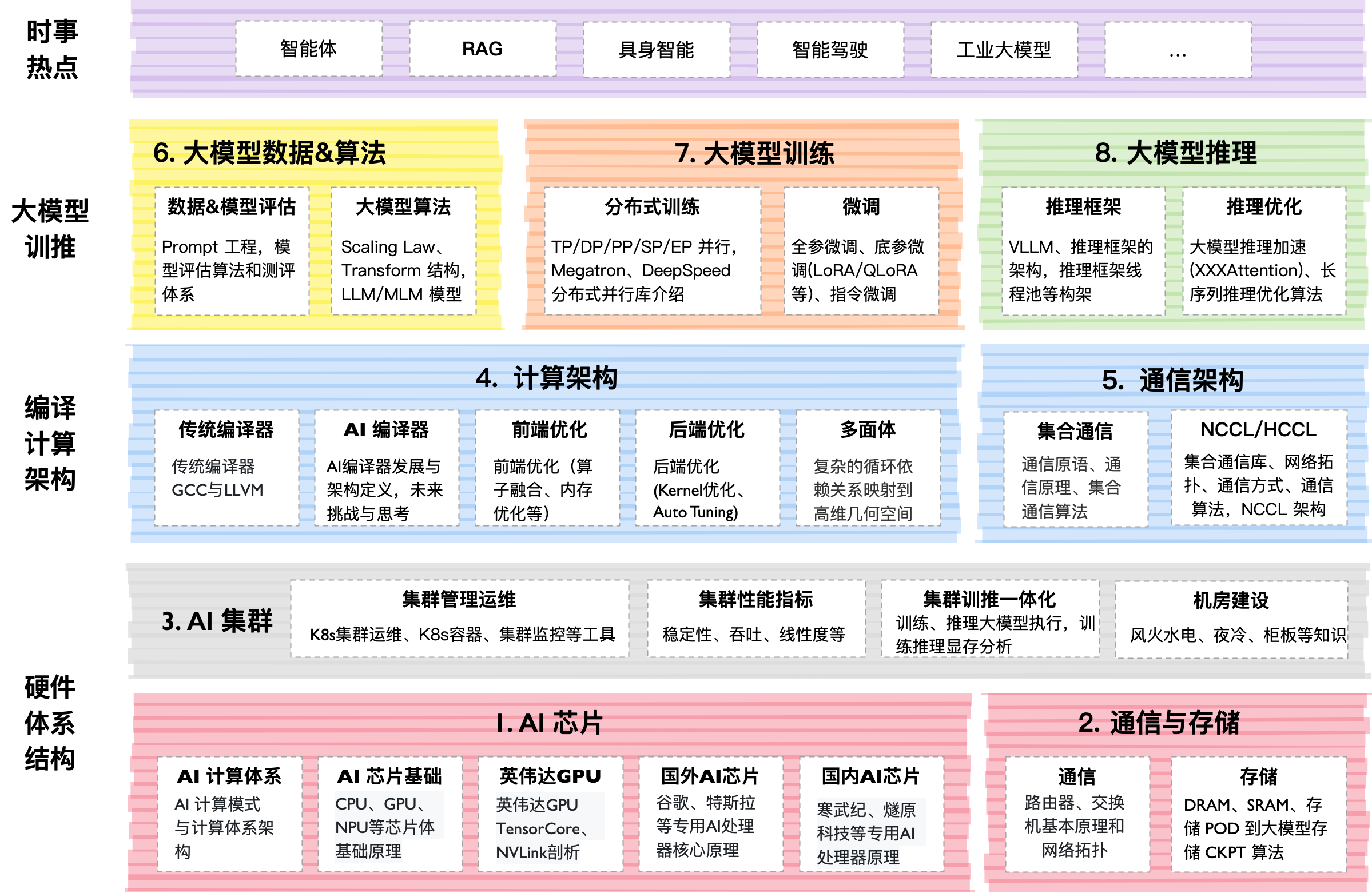
Technische Binnenwerken
Het project leeft in een "levend boek"-formaat. De hoofdinhoud is georganiseerd in directories met nummers (00–07). Binnen elk zijn Markdown-bestanden met uitleg, PDF-slides en Jupyter-notebooks.
Wat mijn aandacht trok:
- Praktijk: Er is code voor het implementeren van Flash Attention van scratch.
- Diepgang: Dekking van Scaling Laws — de wiskundige wetten die voorspellen hoeveel slimmer een model wordt als je het meer data en GPU's geeft.
- Schaal: De hele repository weegt ongeveer 10 GB vanwege de overvloed aan high-resolution graphics en diagrammen. De auteur raadt zelfs aan om alleen de benodigde delen te downloaden via Releases.
Waarom je dit zou moeten leren
De ML-wereld beweegt snel weg van "gewoon trainen" naar complexe engineering-systemen. Tegenwoordig is wat gevraagd wordt niet iemand die weet hoe je model.fit() aanroept, maar iemand die begrijpt hoe je door een GPU naar een container gaat, resource monitoring in K8s opzet, en geheugengebruik optimaliseert door gradient checkpointing.
AIInfra is een gratis ticket naar deze exclusieve club van systeemengineers. Zelfs als je niet van plan bent om je eigen ChatGPT te bouwen, zal kennis van geheugenarchitectuur en netwerkprotocollen je ver boven elke gewone datawetenschapper uit laten steken.
Waar te beginnen
Als je besluit om te duiken, probeer dan niet alles in één keer te lezen. Ik raad dit pad aan:
- Bekijk sectie
04Trainom de magie van parallellisme te begrijpen. - Download de notebook van
Transformerin sectie06AlgoDataen probeer deze lokaal uit te voeren. - Bekijk de slides over inferentie in
05Infer— dit is de basis voor elke backend-ontwikkelaar die met AI werkt.
Het project wordt constant bijgewerkt, en hoewel het chaotisch kan lijken door de mix van talen, is het de meest uitgebreide kennisaggregator over AI-infrastructuur die vandaag beschikbaar is. Is het de moeite waard om te bestuderen? Absoluut, als je van plan bent langer in de industrie te blijven dan de huidige hype aanhoudt.
Gerelateerde projecten