How Neural Network Giants Work Under the Hood
When I first tried to understand how models like Llama or DeepSeek are trained on thousands of GPUs, I hit a wall. PyTorch tutorials explain how to train a cat classifier, but they stay silent on how to make ten thousand GPUs communicate with each other without delays. The AIInfra project is exactly the resource that developers need when they decide to look under the hood of large language models (LLMs).
What Is This Beast
AIInfra (AI Infrastructure) is a massive educational repository that breaks down step by step how neural network infrastructure works. Its author, known in the community as ZOMI, has brought together everything: from the physical design of servers and network switches to distributed training algorithms and inference strategies.
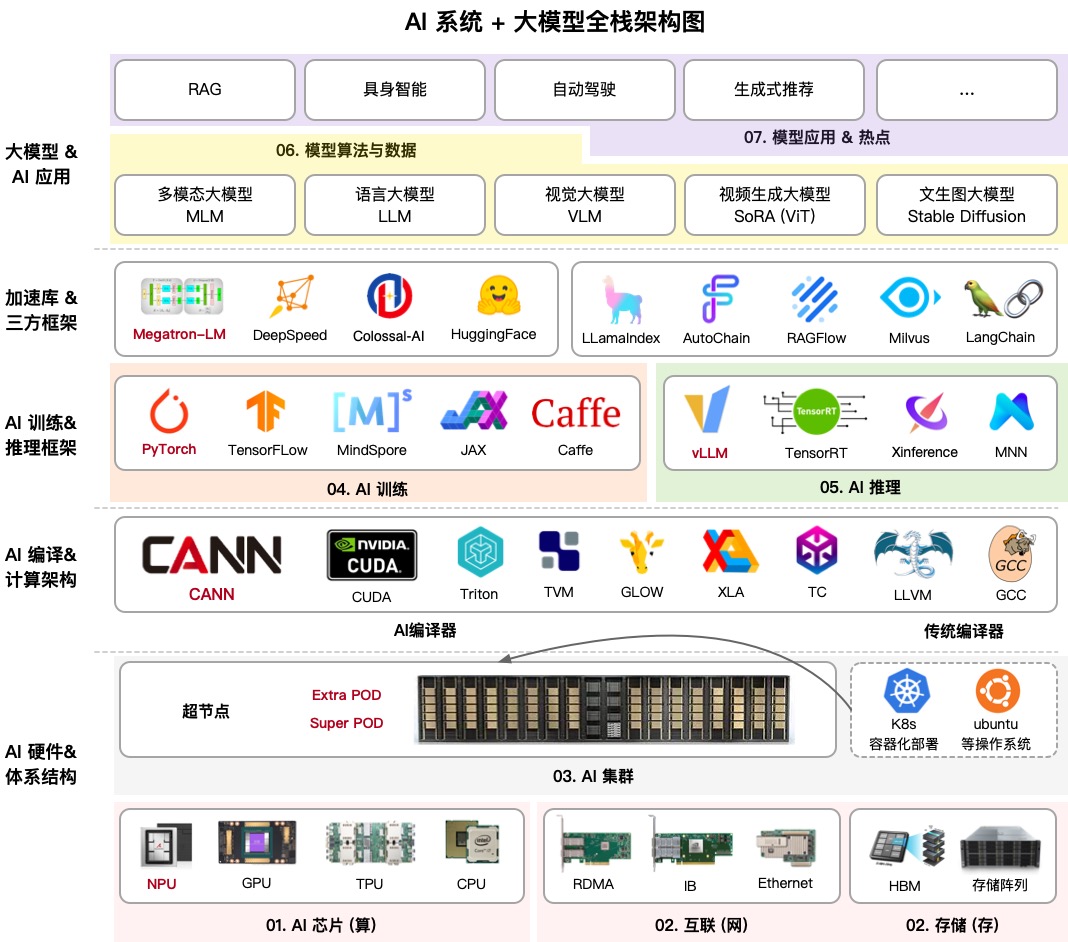
If you thought it was all about writing Python code, this project will surprise you. It covers cooling server racks in data centers, InfiniBand network topologies, and why regular Ethernet can't handle training modern LLMs. This is a complete knowledge map for those who want to call themselves ML engineers or systems architects in the AI era.
Who This Guide Is For
The project will be useful for those who feel cramped within the limits of simply using OpenAI or Anthropic APIs. If you need to:
- Understand why your model trains slowly even though you bought powerful GPUs.
- Figure out how data, tensor, and pipeline parallelism work.
- Set up your own Kubernetes cluster for neural network workloads.
Interestingly, the author doesn't just provide theory but also includes Jupyter notebooks and slides. Some content is in Chinese, but the code and English terms in diagrams are intuitive, and modern translators easily handle the rest.
Five Levels of Diving Into AIInfra
The repository is broken down into logical modules. I've highlighted the ones that seemed most useful for practice.
1. Hardware and Clusters
Here you get the basics: how server nodes are structured, how cooling works, and why GPUs/NPUs behave differently. The section on 10,000-card clusters is especially useful. In my practice, I rarely need to work at such scales, but understanding how resources are distributed there helps optimize even smaller setups better.
2. Communications and Storage
Massive models can't just be sent over the network. AIInfra thoroughly explains collective communication libraries like NCCL (from NVIDIA) and HCCL (from Huawei). If you've ever seen error NCCL TIMEOUT, this section will help you understand exactly where in the network stack things went wrong.
3. Distributed Training
This is the "meat" of the project. The author dissects PyTorch DDP (Distributed Data Parallel) and DeepSpeed down to the bone. There are even practical examples:
# Пример из материалов: создание своего DDP с нуля
# Помогает понять, что под капотом у стандартных библиотек
import torch.distributed as dist
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# Дальше идет логика распределения градиентов
Here they also explain ZeRO (Zero Redundancy Optimizer) technology, which enables training models that don't fit into a single GPU's memory by splitting optimizer states.
4. Model Architectures: Transformer and MoE
Instead of simply saying "use Attention," the project shows how to implement its variations (MHA, GQA, MLA) and how sparse models (Mixture of Experts) are structured. The latter is critically important now, as almost all top open-source models are built on this principle.
5. Inference and Optimization
Training is only half the battle. You also need the model to respond quickly. AIInfra covers KV-caching, quantization, and distillation. These are the very tricks that let you run a powerful model on home hardware or cheap cloud instances.
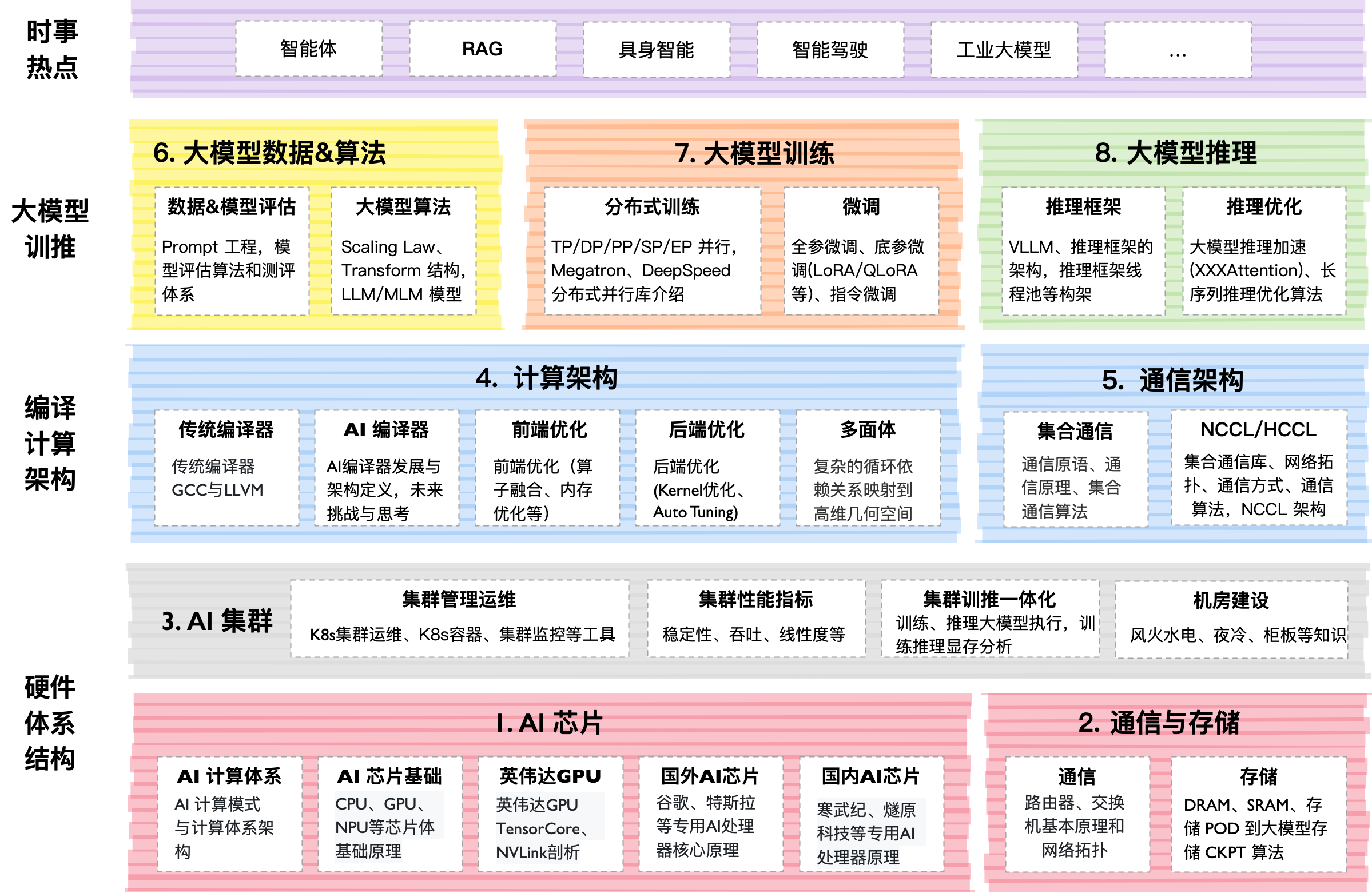
Technical Internals
The project lives in a "living book" format. The main content is organized in directories by numbers (00–07). Inside each are Markdown files with explanations, PDF slides, and Jupyter notebooks.
What caught my attention:
- Practice: There's code for implementing Flash Attention from scratch.
- Depth: Coverage of Scaling Laws — the mathematical laws that predict how much smarter a model will become if you give it more data and GPUs.
- Scale: The entire repository weighs about 10 GB due to the abundance of high-resolution graphics and diagrams. The author even recommends downloading only the needed parts via Releases.
Why You Should Learn This
The ML world is quickly moving away from "just training" to complex engineering systems. Today, what's in demand is not someone who knows how to call model.fit(), but someone who understands how to pass through a GPU to a container, set up resource monitoring in K8s, and optimize memory consumption through gradient checkpointing.
AIInfra is a free ticket to this exclusive club of systems engineers. Even if you don't plan to build your own ChatGPT, knowledge of memory architecture and network protocols will put you head and shoulders above any ordinary data scientist.
Where to Start
If you decide to dive in, don't try to read everything at once. I recommend this path:
- Check out section
04Trainto understand the magic of parallelism. - Download the notebook from
Transformerin section06AlgoDataand try running it locally. - Watch the slides on inference in
05Infer— this is the foundation for any backend developer working with AI.
The project is constantly updated, and although it may seem chaotic due to the mix of languages, it's the most comprehensive knowledge aggregator on AI infrastructure available today. Is it worth studying? Absolutely, if you plan to stay in the industry longer than the current hype lasts.
Powiązane projekty