Como Funcionam os Gigantes das Redes Neurais nos Bastidores
Quando tentei entender pela primeira vez como modelos como Llama ou DeepSeek são treinados em milhares de GPUs, encontrei uma barreira. Tutoriais de PyTorch explicam como treinar um classificador de gatos, mas ficam em silêncio sobre como fazer dez mil GPUs se comunicarem sem atrasos. O projeto AIInfra é exatamente o recurso que desenvolvedores precisam quando decidem olhar sob o capô dos modelos de linguagem grandes (LLMs).
O Que É Essa Besta
AIInfra (AI Infrastructure) é um enorme repositório educacional que detalha passo a passo como a infraestrutura de redes neurais funciona. Seu autor, conhecido na comunidade como ZOMI, reuniutudo: desde o design físico de servidores e switches de rede até algoritmos de treinamento distribuído e estratégias de inferência.
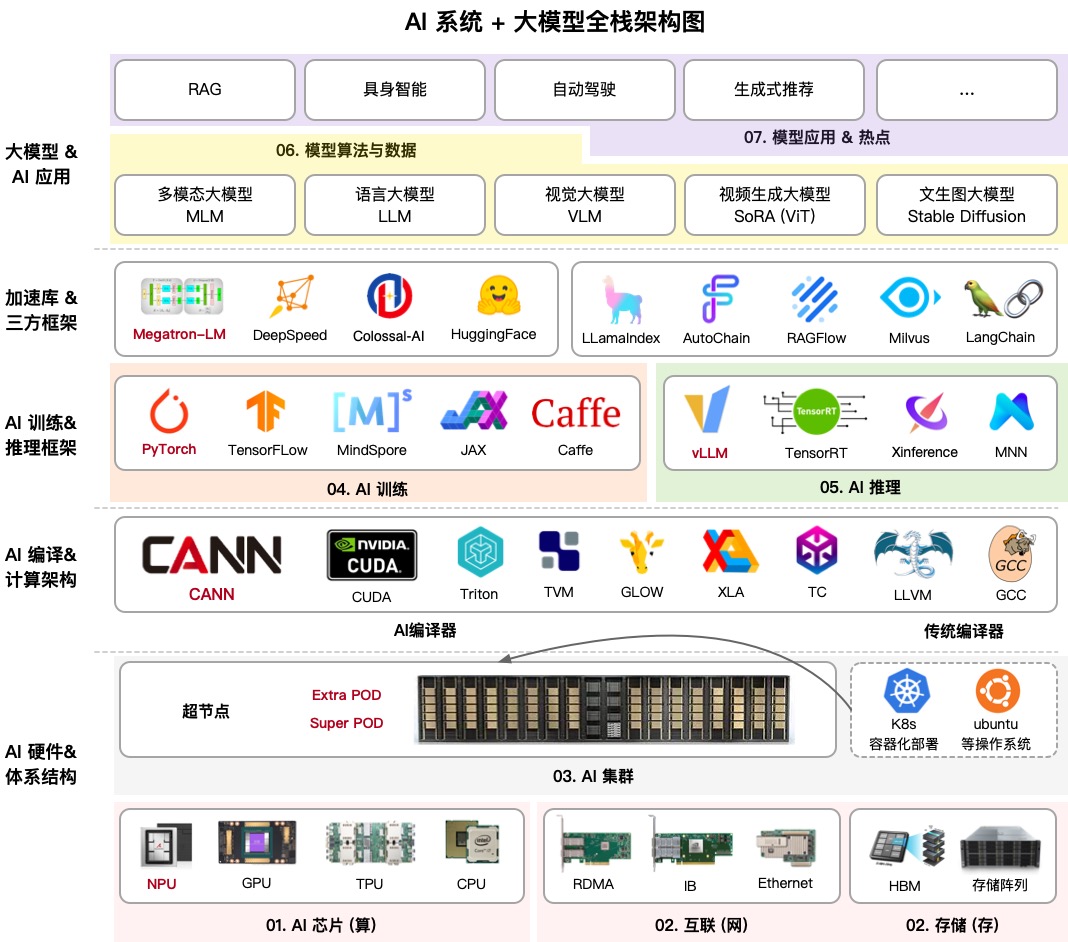
Se você pensou que era tudo sobre escrever código Python, este projeto vai surpreendê-lo. Ele cobre o resfriamento de racks de servidores em data centers, topologias de rede InfiniBand, e por que o Ethernet comum não consegue lidar com o treinamento de LLMs modernos. Este é um mapa de conhecimento completo para quem quer se chamar de engenheiro de ML ou arquiteto de sistemas na era da IA.
Para Quem Este Guia É
O projeto será útil para quem se sente limitado dentro dos limites de simplesmente usar APIs da OpenAI ou Anthropic. Se você precisa:
- Entender por que seu modelo treina lentamente mesmo tendo comprado GPUs poderosas.
- Descobrir como funcionam paralelismo de dados, tensores e pipeline.
- Configurar seu próprio cluster Kubernetes para cargas de trabalho de redes neurais.
Curiosamente, o autor não fornece apenas teoria, mas também inclui notebooks Jupyter e slides. Parte do conteúdo está em chinês, mas o código e termos em inglês nos diagramas são intuitivos, e tradutores modernos lidam facilmente com o resto.
Cinco Níveis de Imersão no AIInfra
O repositório é dividido em módulos lógicos. Destaquei os que pareceram mais úteis para a prática.
1. Hardware e Clusters
Aqui você obtém o básico: como os nós de servidor são estruturados, como o resfriamento funciona, e por que GPUs/NPUs se comportam de forma diferente. A seção sobre clusters de 10.000 placas é especialmente útil. Na minha prática, raramente preciso trabalhar em escalas assim, mas entender como os recursos são distribuídos lá ajuda a otimizar até configurações menores melhor.
2. Comunicações e Armazenamento
Modelos massivos não podem simplesmente ser enviados pela rede. O AIInfra explica detalhadamente bibliotecas de comunicação coletiva como NCCL (da NVIDIA) e HCCL (da Huawei). Se você já viu o erro NCCL TIMEOUT, esta seção ajudará você a entender exatamente onde na pilha de rede as coisas deram errado.
3. Treinamento Distribuído
Esta é a "carne" do projeto. O autor disseca PyTorch DDP (Distributed Data Parallel) e DeepSpeed até o osso. Há até exemplos práticos:
# Пример из материалов: создание своего DDP с нуля
# Помогает понять, что под капотом у стандартных библиотек
import torch.distributed as dist
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# Дальше идет логика распределения градиентов
Aqui eles também explicam a tecnologia ZeRO (Zero Redundancy Optimizer), que permite treinar modelos que não cabem na memória de uma única GPU, dividindo os estados do otimizador.
4. Arquiteturas de Modelos: Transformer e MoE
Em vez de simplesmente dizer "use Attention," o projeto mostra como implementar suas variações (MHA, GQA, MLA) e como modelos esparsos (Mixture of Experts) são estruturados. Isso é criticamente importante agora, pois quase todos os principais modelos de código aberto são construídos nesse princípio.
5. Inferência e Otimização
Treinar é apenas metade da batalha. Você também precisa que o modelo responda rapidamente. O AIInfra cobre KV-caching, quantização e destilação. Esses são os truques que permitem executar um modelo poderoso em hardware doméstico ou instâncias de nuvem baratas.
Entraves Técnicos
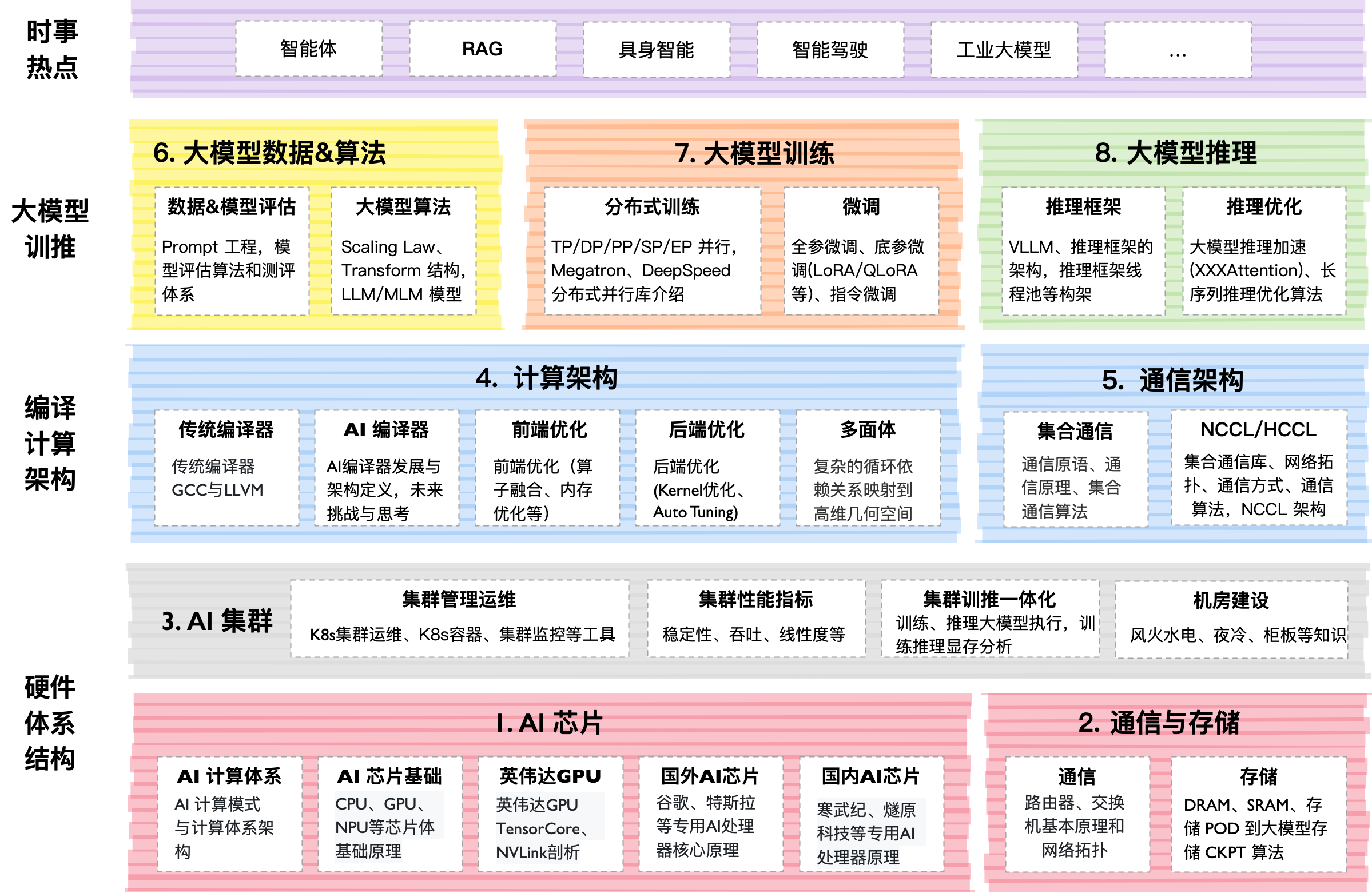
O projeto vive em um formato de "livro vivo". O conteúdo principal é organizado em diretórios por números (00–07). Dentro de cada um estão arquivos Markdown com explicações, slides em PDF e notebooks Jupyter.
O que chamou minha atenção:
- Prática: Há código para implementar Flash Attention do zero.
- Profundidade: Cobertura de Scaling Laws — as leis matemáticas que preveem quão mais inteligente um modelo ficará se você fornecer mais dados e GPUs.
- Escala: O repositório inteiro pesa cerca de 10 GB devido à abundância de gráficos e diagramas de alta resolução. O autor até recomenda baixar apenas as partes necessárias via Releases.
Por Que Você Deve Aprender Isso
O mundo de ML está se movendo rapidamente de "apenas treinar" para sistemas de engenharia complexos. Hoje, o que está em demanda não é alguém que sabe como chamar model.fit(), mas alguém que entende como passar por uma GPU para um container, configurar monitoramento de recursos no K8s e otimizar consumo de memória através de gradient checkpointing.
AIInfra é um ingresso gratuito para este clube exclusivo de engenheiros de sistemas. Mesmo que você não planeje construir seu próprio ChatGPT, conhecimento de arquitetura de memória e protocolos de rede o colocará muito à frente de qualquer cientista de dados comum.
Por Onde Começar
Se você decidir mergulhar, não tente ler tudo de uma vez. Recomendo este caminho:
- Dê uma olhada na seção
04Trainpara entender a mágica do paralelismo. - Baixe o notebook de
Transformerna seção06AlgoDatae tente executá-lo localmente. - Assista aos slides sobre inferência em
05Infer— esta é a base para qualquer desenvolvedor backend trabalhando com IA.
O projeto é constantemente atualizado, e embora possa parecer caótico devido à mistura de idiomas, é o agregador de conhecimento mais completo sobre infraestrutura de IA disponível hoje. Vale a pena estudar? Com certeza, se você planeja permanecer na indústria por mais tempo do que a atual euforia durar.
Projetos relacionados