Comment fonctionnent les géants des réseaux de neurones sous le capot
Quand j'ai essayé pour la première fois de comprendre comment des modèles comme Llama ou DeepSeek sont entraînés sur des milliers de GPU, je me suis heurté à un mur. Les tutoriels PyTorch expliquent comment entraîner un classificateur de chats, mais ils restent muets sur la façon de faire communiquer dix mille GPU entre eux sans délais. Le projet AIInfra est exactement la ressource dont les développeurs ont besoin lorsqu'ils décident de regarder sous le capot des grands modèles de langage (LLM).
Qu'est-ce que cette bête
AIInfra (AI Infrastructure) est un vaste dépôt éducatif qui décompose étape par étape le fonctionnement de l'infrastructure des réseaux de neurones. Son auteur, connu dans la communauté sous le nom de ZOMI, a rassemblé tout : de la conception physique des serveurs et des commutateurs réseau aux algorithmes d'entraînement distribué et aux stratégies d'inférence.
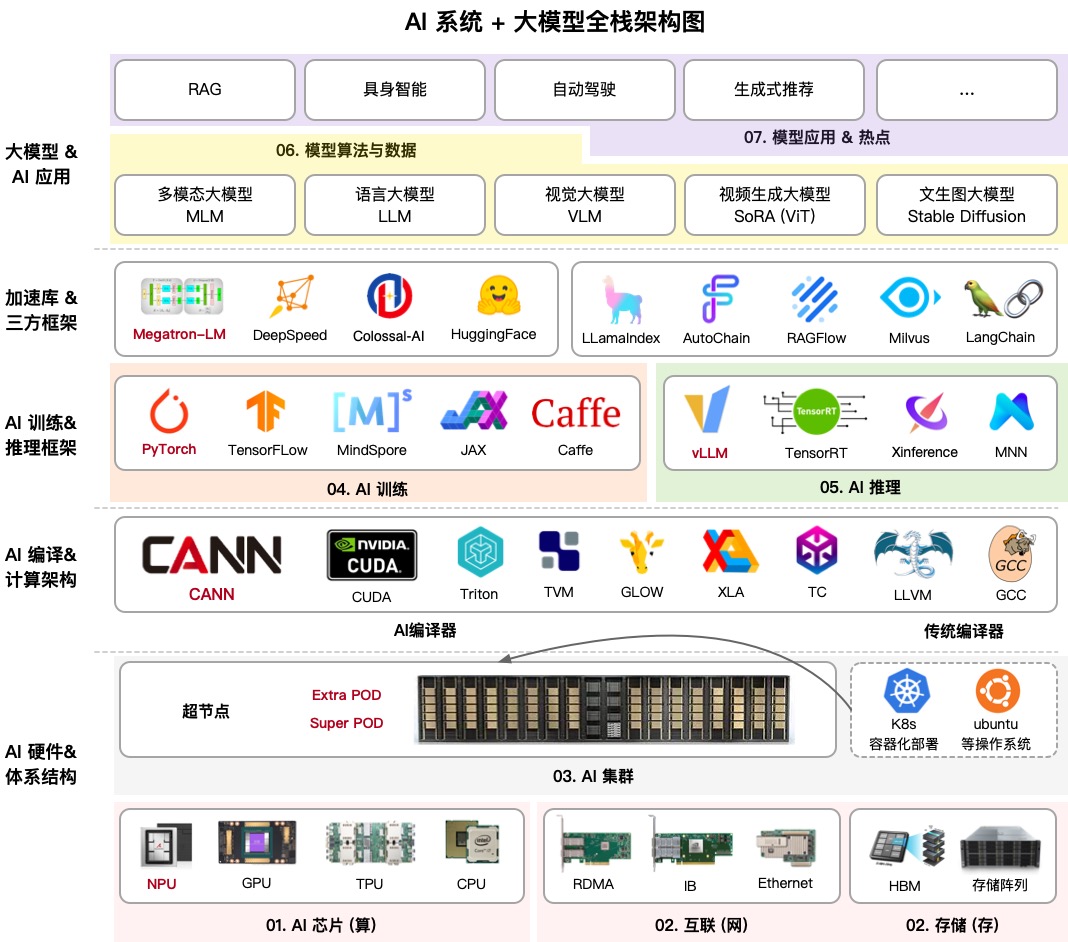
Si vous pensiez que c'était tout simplement une question d'écriture de code Python, ce projet va vous surprendre. Il couvre le refroidissement des racks de serveurs dans les centres de données, les topologies de réseau InfiniBand, et pourquoi l'Ethernet classique ne peut pas gérer l'entraînement des LLM modernes. C'est une carte de connaissances complète pour ceux qui veulent s'appeler ingénieurs ML ou architectes de systèmes à l'ère de l'IA.
À qui ce guide est destiné
Le projet sera utile à ceux qui se sentent à l'étroit dans les limites de la simple utilisation des API OpenAI ou Anthropic. Si vous avez besoin de :
- Comprendre pourquoi votre modèle s'entraîne lentement alors que vous avez acheté des GPU puissants.
- Comprendre comment fonctionnent les parallélismes de données, de tenseurs et de pipelines.
- Configurer votre propre cluster Kubernetes pour les charges de travail des réseaux de neurones.
Curieusement, l'auteur ne se contente pas de fournir de la théorie mais inclut également des notebooks Jupyter et des diapositives. Certains contenus sont en chinois, mais le code et les termes anglais dans les diagrammes sont intuitifs, et les traducteurs modernes gèrent facilement le reste.
Cinq niveaux d'immersion dans AIInfra
Le dépôt est divisé en modules logiques. J'ai mis en évidence ceux qui m'ont semblé les plus utiles pour la pratique.
1. Matériel et grappes
Ici, vous obtenez les bases : comment les nœuds de serveurs sont structurés, comment le refroidissement fonctionne, et pourquoi les GPU/NPU se comportent différemment. La section sur les grappes de 10 000 cartes est particulièrement utile. Dans ma pratique, j'ai rarement besoin de travailler à cette échelle, mais comprendre comment les ressources sont distribuées là-bas aide à optimiser même des configurations plus petites.
2. Communications et stockage
Les modèles massifs ne peuvent pas simplement être envoyés sur le réseau. AIInfra explique en détail les bibliothèques de communication collective comme NCCL (de NVIDIA) et HCCL (de Huawei). Si vous avez déjà vu l'erreur NCCL TIMEOUT, cette section vous aidera à comprendre exactement où dans la pile réseau les choses ont mal tourné.
3. Entraînement distribué
C'est le « cœur » du projet. L'auteur dissecte PyTorch DDP (Distributed Data Parallel) et DeepSpeed jusqu'à l'os. Il y a même des exemples pratiques :
# Пример из материалов: создание своего DDP с нуля
# Помогает понять, что под капотом у стандартных библиотек
import torch.distributed as dist
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# Дальше идет логика распределения градиентов
Ici, il explique également la technologie ZeRO (Zero Redundancy Optimizer), qui permet d'entraîner des modèles qui ne rentrent pas dans la mémoire d'un seul GPU en divisant les états de l'optimiseur.
4. Architectures de modèles : Transformer et MoE
Au lieu de simplement dire « utilisez Attention », le projet montre comment implémenter ses variations (MHA, GQA, MLA) et comment les modèles creux (Mixture of Experts) sont structurés. Ces derniers sont actuellement d'une importance critique, car presque tous les meilleurs modèles open source sont construits sur ce principe.
5. Inférence et optimisation
L'entraînement n'est que la moitié de la bataille. Vous avez également besoin que le modèle réponde rapidement. AIInfra couvre le KV-caching, la quantification et la distillation. Ce sont précisément les astuces qui vous permettent d'exécuter un modèle puissant sur du matériel domestique ou des instances cloud bon marché.
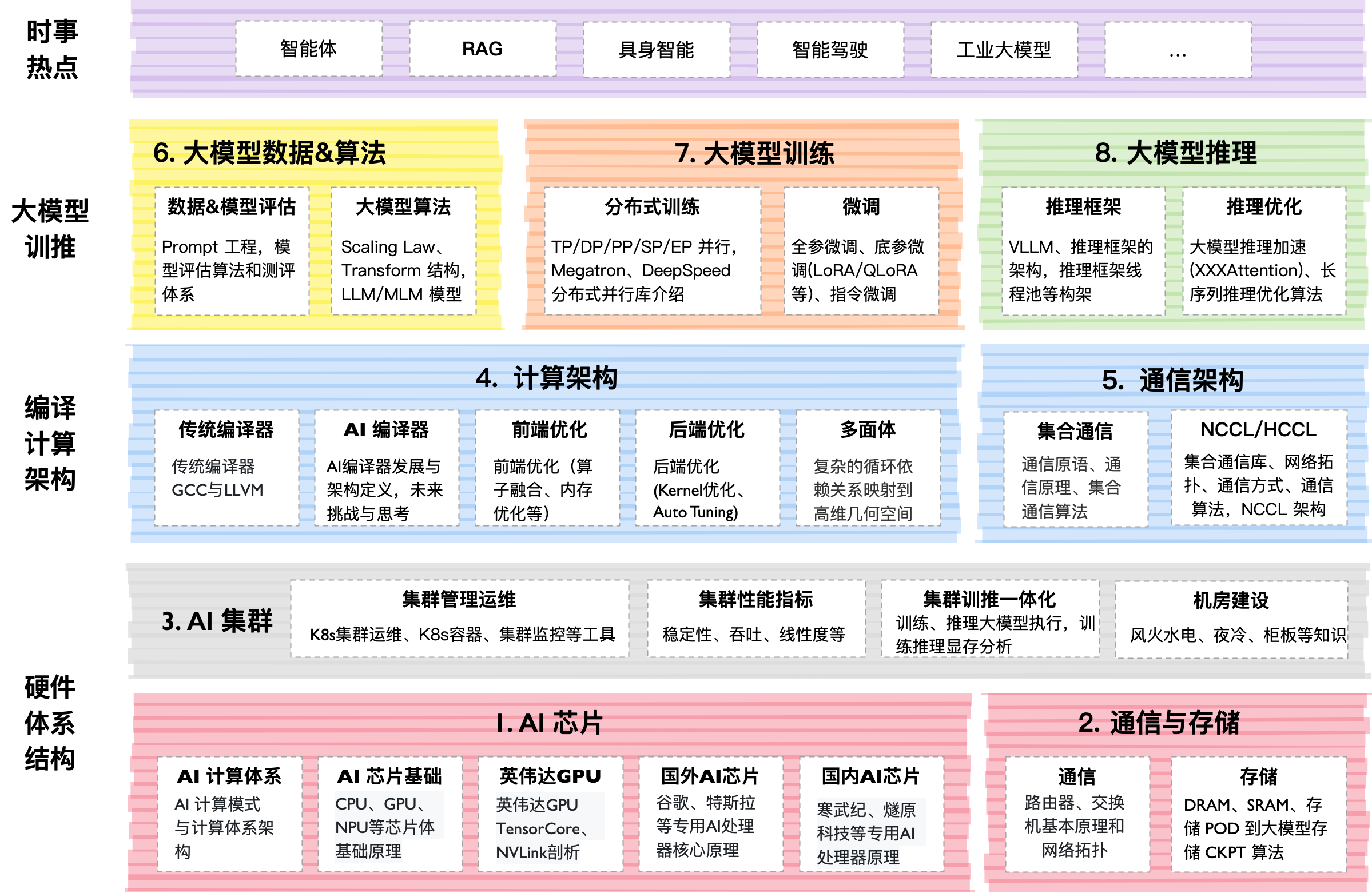
Les rouages techniques
Le projet existe dans un format de « livre vivant ». Le contenu principal est organisé dans des répertoires par numéros (00–07). À l'intérieur de chacun se trouvent des fichiers Markdown avec des explications, des diapositives PDF et des notebooks Jupyter.
Ce qui a retenu mon attention :
- Pratique : Il y a du code pour implémenter Flash Attention from scratch.
- Profondeur : Couverture des Scaling Laws — les lois mathématiques qui prédisent à quel point un modèle deviendra plus intelligent si vous lui donnez plus de données et de GPU.
- Échelle : L'ensemble du dépôt pèse environ 10 Go en raison de l'abondance de graphiques et de diagrammes haute résolution. L'auteur recommande même de ne télécharger que les parties nécessaires via les Releases.
Pourquoi vous devriez apprendre cela
Le monde du ML s'éloigne rapidement du « simple entraînement » vers des systèmes d'ingénierie complexes. Aujourd'hui, ce qui est demandé n'est pas quelqu'un qui sait appeler model.fit(), mais quelqu'un qui comprend comment traverser un GPU vers un conteneur, configurer la surveillance des ressources dans K8s, et optimiser la consommation de mémoire par le gradient checkpointing.
AIInfra est un billet gratuit pour ce club exclusif d'ingénieurs systèmes. Même si vous ne prévoyez pas de construire votre propre ChatGPT, la connaissance de l'architecture mémoire et des protocoles réseau vous placera une tête et des épaules au-dessus de n'importe quel scientifique de données ordinaire.
Par où commencer
Si vous décidez de vous immerger, n'essayez pas de tout lire d'un coup. Je recommande ce chemin :
- Consultez la section
04Trainpour comprendre la magie du parallélisme. - Téléchargez le notebook de
Transformerdans la section06AlgoDataet essayez de l'exécuter localement. - Regardez les diapositives sur l'inférence dans
05Infer— c'est la base pour tout développeur backend travaillant avec l'IA.
Le projet est constamment mis à jour, et bien qu'il puisse sembler chaotique en raison du mélange de langues, c'est l'agrégateur de connaissances le plus complet sur l'infrastructure IA disponible aujourd'hui. Cela vaut-il la peine de l'étudier ? Absolument, si vous prévoyez de rester dans l'industrie plus longtemps que l'engouement actuel.
Projets similaires