神经网络巨头是如何运作的
当我第一次尝试理解 Llama 或 DeepSeek 这样的模型是如何在数千个 GPU 上训练时,我遇到了瓶颈。PyTorch 教程教如何训练一个猫分类器,但对如何让一万个 GPU 相互通信且无延迟却只字未提。AIInfra 项目正是开发者想要深入了解大语言模型(LLM)内部运作机制时所需要的资源。
这是什么怪物
AIInfra(AI 基础设施)是一个庞大的教育资源库,逐步解析神经网络基础设施的运作原理。其作者在社区中被称为 ZOMI,涵盖了从服务器和网络交换机的物理设计到分布式训练算法和推理策略的所有内容。
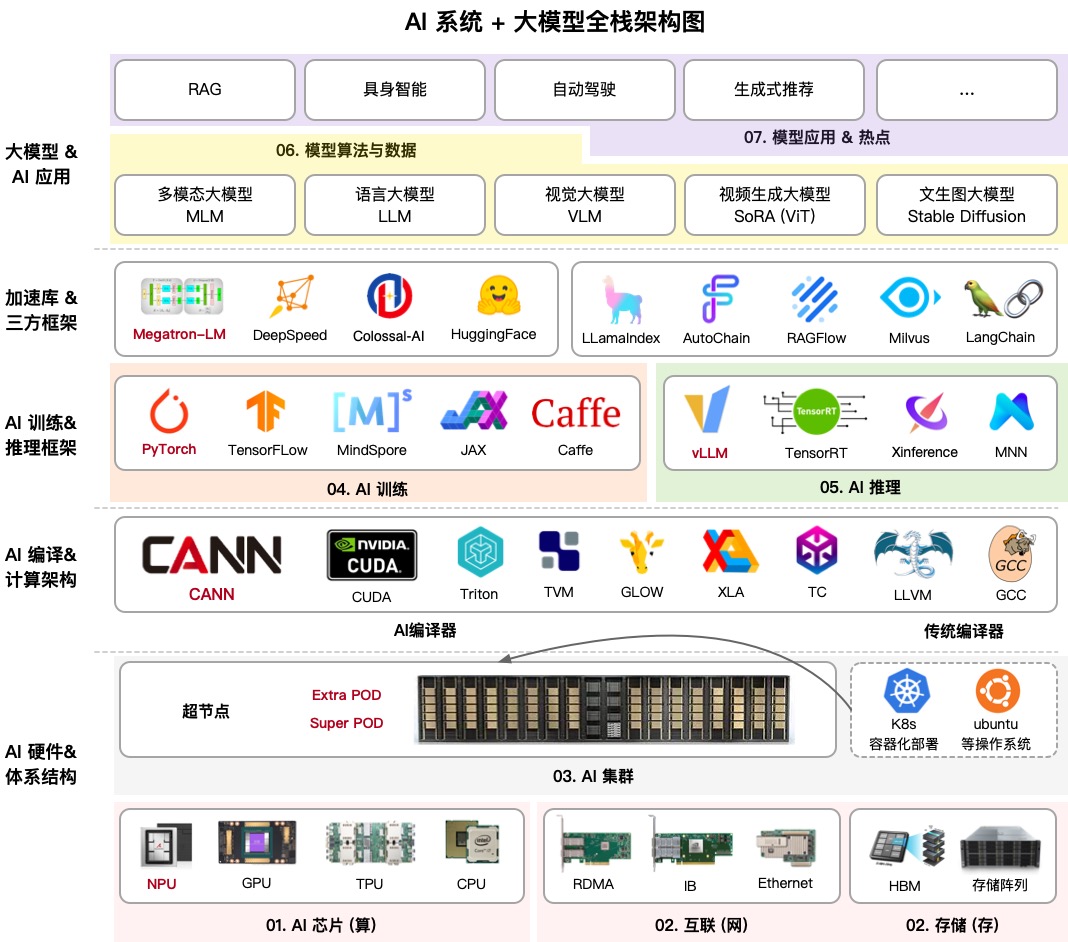
如果你以为这只是关于编写 Python 代码,这个项目会让你大吃一惊。它涵盖了数据中心服务器机架的冷却、InfiniBand 网络拓扑,以及为什么普通以太网无法处理现代 LLM 的训练。对于那些想称自己为 ML 工程师或 AI 时代系统架构师的人来说,这是一份完整的知识地图。
本指南的目标读者
这个项目对那些感到仅使用 OpenAI 或 Anthropic API 受限的人会很有用。如果你需要:
- 理解为什么买了强大 GPU 后模型训练还是很慢。
- 弄清楚数据并行、张量并行和流水线并行是如何工作的。
- 为神经网络工作负载搭建自己的 Kubernetes 集群。
有趣的是,作者不仅提供理论,还包含 Jupyter notebooks 和幻灯片。有些内容是中文的,但代码和图表中的英文术语很直观,现代翻译工具能轻松处理其余部分。
深入 AIInfra 的五个层次
该仓库被划分为逻辑模块。我重点标注了那些对实践最有用的部分。
1. 硬件与集群
这里涵盖了基础知识:服务器节点的结构、冷却系统的工作原理,以及 GPU/NPU 为何表现不同。关于万卡集群的部分尤其有价值。在我的实践中,虽然很少需要处理这种规模,但理解资源分配方式能帮助优化更小规模的配置。
2. 通信与存储
大型模型无法直接通过网络传输。AIInfra 详细解释了 NCCL(来自 NVIDIA)和 HCCL(来自华为)等集合通信库。如果你曾遇到过错误 NCCL TIMEOUT,这部分内容能帮助你准确定位网络堆栈中出现问题的位置。
3. 分布式训练
这是该项目的核心内容。作者深入剖析了 PyTorch DDP(分布式数据并行)和 DeepSpeed,甚至包含实际案例:
这里还解释了 ZeRO(零冗余优化器)技术,它通过分割优化器状态来实现单 GPU 内存无法容纳的模型训练。
4. 模型架构:Transformer 与 MoE
该项目没有简单地说"使用 Attention",而是展示了如何实现其变体(MHA、GQA、MLA)以及稀疏模型(混合专家)的结构。后者现在至关重要,因为几乎所有顶级开源模型都基于这一原理构建。
5. 推理与优化
训练只是成功的一半。你还需要模型能快速响应。AIInfra 涵盖了 KV-缓存、量化和蒸馏。这些技巧能让你在家用硬件或廉价云实例上运行强大的模型。
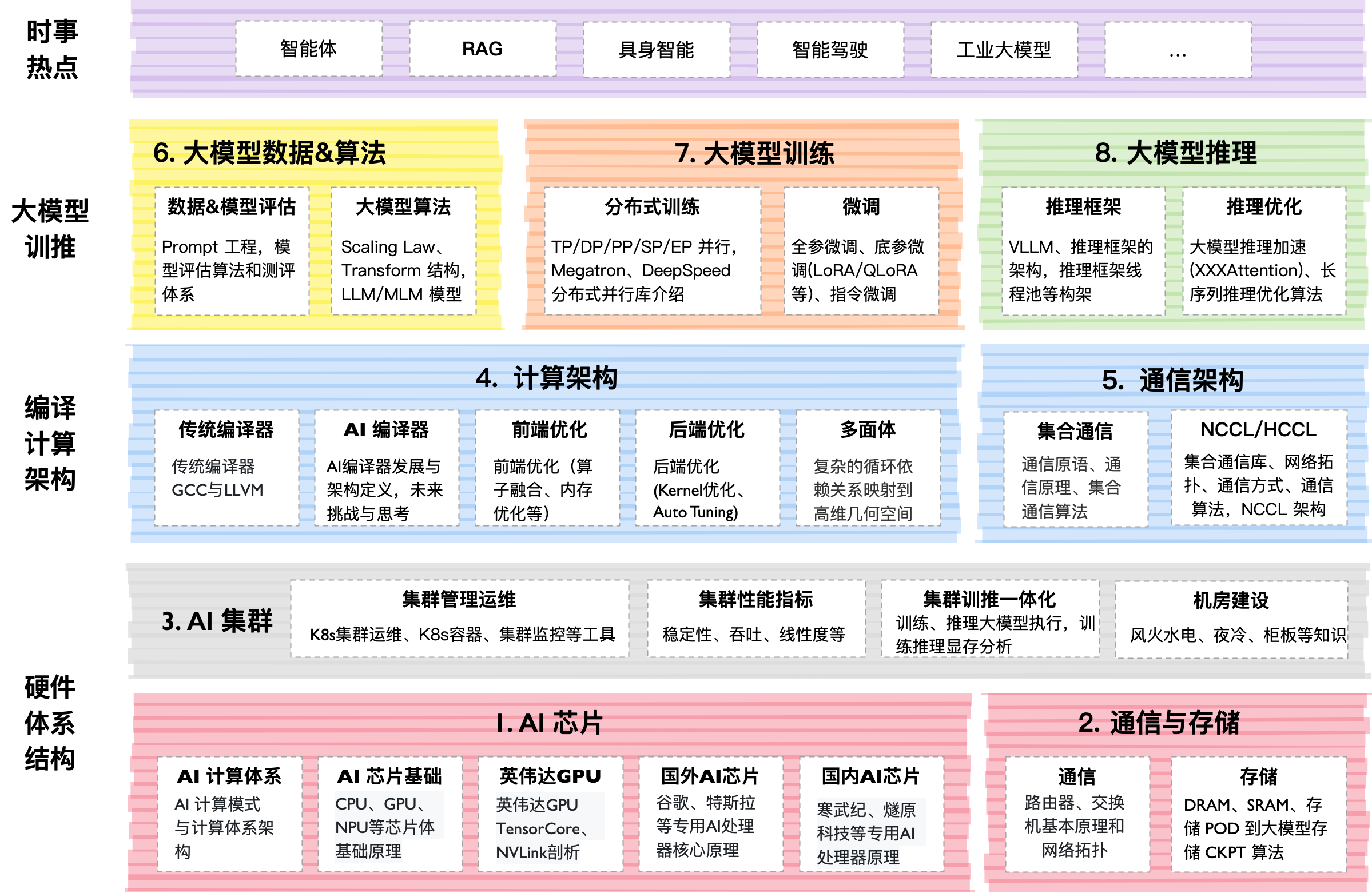
技术内幕
该项目采用"活书籍"形式。主要内容按数字目录组织(00–07),每个目录下包含 Markdown 说明文件、PDF 幻灯片和 Jupyter notebooks。
引起我注意的内容:
- 实践:有从零实现 Flash Attention 的代码。
- 深度:涵盖扩展定律——预测如果给模型更多数据和 GPU,它会变得多聪明的数学定律。
- 规模:整个仓库约 10 GB,因为包含大量高分辨率图形和图表。作者甚至建议通过 Releases 只下载需要的部分。
为什么要学习这些
ML 世界正在快速从"单纯训练"转向复杂的工程系统。如今业界需要的不再是只会调用 model.fit() 的人,而是理解 GPU 到容器如何传递、K8s 资源监控如何设置、梯度检查点如何优化内存消耗的系统工程师。
AIInfra 是进入这个专属系统工程师圈子的免费门票。即使不打算构建自己的 ChatGPT,掌握内存架构和网络协议知识也能让你远超普通数据科学家。
从哪里开始
如果决定深入学习,不要试图一次性阅读所有内容。我建议按以下路径开始:
- 查看第
04Train节了解并行化的魔力。 - 下载第
06AlgoData节中的第Transformer个 notebook 并尝试在本地运行。 - 观看第
05Infer节中关于推理的幻灯片——这是任何 AI 后端开发者的基础。
项目持续更新中,虽然语言混杂可能显得混乱,但它是目前最全面的 AI 基础设施知识聚合器。值得学习吗?当然,如果你打算在这个行业长期发展而非追逐当前的热潮。
相关项目