ニューラルネットワークの巨人は内部でどのように動くのか
LlamaやDeepSeekのようなモデルが数千個のGPUでどのように学習されるのかを理解しようとしたとき、私は壁にぶつかりました。PyTorchのチュートリアルは猫分類器の訓練方法を教えてくれますが、1万台のGPU同士を遅延なく通信させる方法については沈黙しています。AIInfraプロジェクトは、大規模言語モデル(LLM)の内部構造を覗こうと決めた開発者が必要とする、まさにそのリソースです。
この化け物は何だ
AIInfra(AI Infrastructure)は、ニューラルネットワークインフラがどのように動作するかをステップバイステップで分解した、大規模な教育リポジトリです。コミュニティでZOMIとして知られる作者が、物理的なサーバーやネットワークスイッチの設計から、分散学習アルゴリズム、推論戦略まで、すべてを一箇所にまとめました。
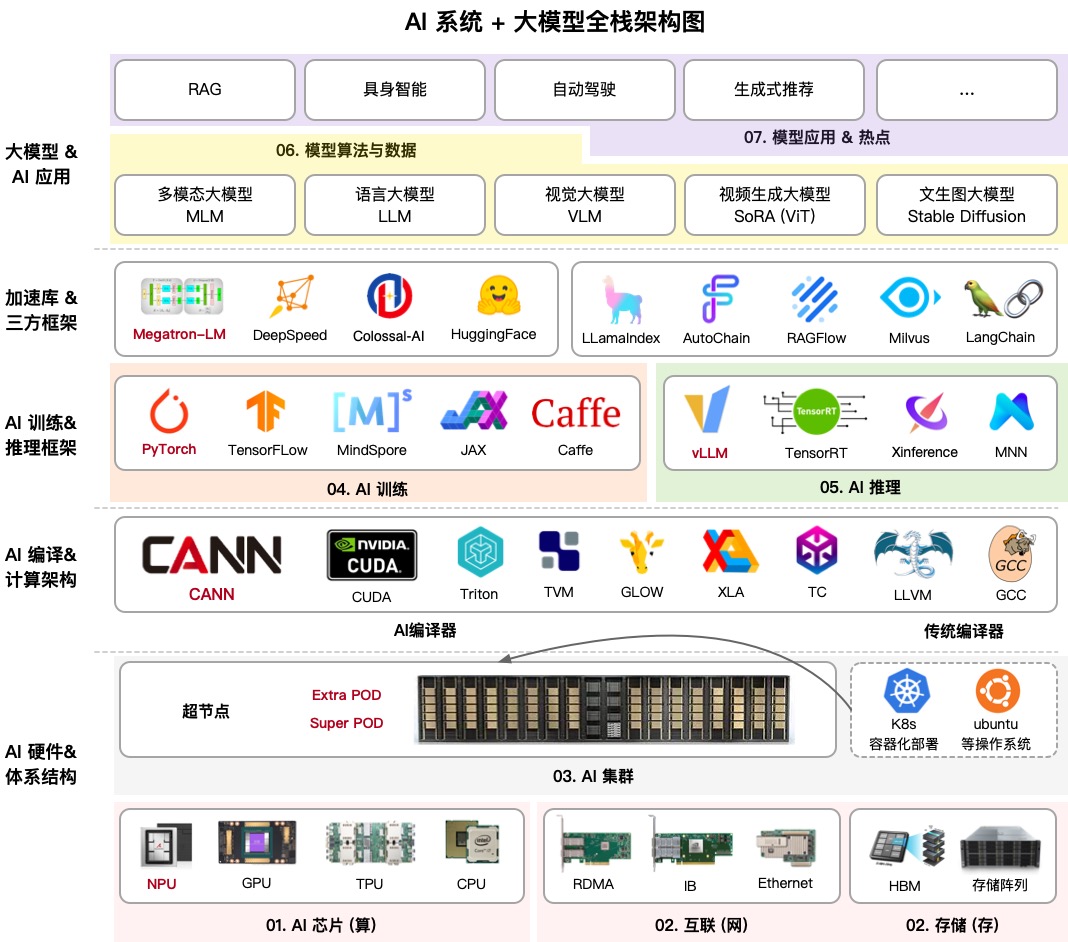
Pythonのコードを書くだけだと思っていたら、このプロジェクトは驚かれるでしょう。データセンターのサーバー・ラックの冷却、InfiniBandネットワークトポロジー、なぜ通常のEthernetでは現代のLLMの訓練に対応できないのかまでカバーしています。これは、AI時代のMLエンジニアやシステムアーキテクトを名乗りたい人ための完全な知識マップです。
このガイドの対象者是
OpenAIやAnthropicのAPIを単に使う範囲では窮屈に感じている人に、このプロジェクトは役立ちます。以下が必要な場合:
- 強力なGPUを買ったのにモデルの訓練が遅い理由を理解したい。
- データ、パイプライン、テンソル並列性がどのように動作するのか弄清楚したい。
- ニューラルネットワークワークロード用に独自のKubernetesクラスターをセットアップしたい。
興味深いことに、作者は単に理論を提供するだけでなく、Jupyterノートブックやスライドも収録しています。コンテンツの一部は中国語ですが、コードや図面の英語用語は直感的で、残りの部分は現代の翻訳者で簡単に処理できます。
AIInfraへの5段階の奥掘り
リポジトリは論理的なモジュールに分かれています。私が実践的に最も有用だと思ったものをハイライトします。
1. ハードウェアとクラスター
ここでは基礎を学びます:サーバーノードの構造、冷却の動作原理、GPU/NPUの異なる動作特性。1万枚カード・クラスターのセクションは特に有用です。私の実践では、このような規模で作業する必要があることは稀ですが、リソースがどのように分散されているかを理解することで、小さなセットアップでさえより適切に最適化できます。
2. 通信とストレージ
大規模なモデルはネットワーク越しに単に送れません。AIInfraはNCCL(NVIDIA製)やHCCL(Huawei製)のような集団通信ライブラリを徹底的に解説しています。エラーNCCL TIMEOUTを見たことがあるなら、このセクションはネットワークスタックのどこで問題が発生したかを正確に理解するのに役立ちます。
3. 分散学習
これがプロジェクトの「核心」です。著者はPyTorch DDP(Distributed Data Parallel)やDeepSpeedを骨太に解剖しています。実践的な例もあります:
# Пример из материалов: создание своего DDP с нуля
# Помогает понять, что под капотом у стандартных библиотек
import torch.distributed as dist
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# Дальше идет логика распределения градиентов
ここではZeRO(Zero Redundancy Optimizer)技術についても解説しています。これは、オプティマイザの状態を分割することで、单个GPUのメモリに収まらないモデルの訓練を可能にする技術です。
4. モデルアーキテクチャ:TransformerとMoE
単に「Attentionを使え」ではなく、プロジェクトのバリエーション(MHA、GQA、MLA)の実装方法和稀疏モデル(Mixture of Experts)の構造を示しています。後者は現在極めて重要です。なぜなら、ほぼすべてのトップオープンソースモデルがこの原則に基づいて構築されているからです。
5. 推論と最適化
訓練は半分にすぎません。モデルが素早く応答する必要もあります。AIInfraはKVキャッシュ、量子化、蒸留をカバーしています。これらは、家庭用ハードウェアや安価なクラウドインスタンスで強力なモデルを実行可能にする、まさにそのテクニックです。
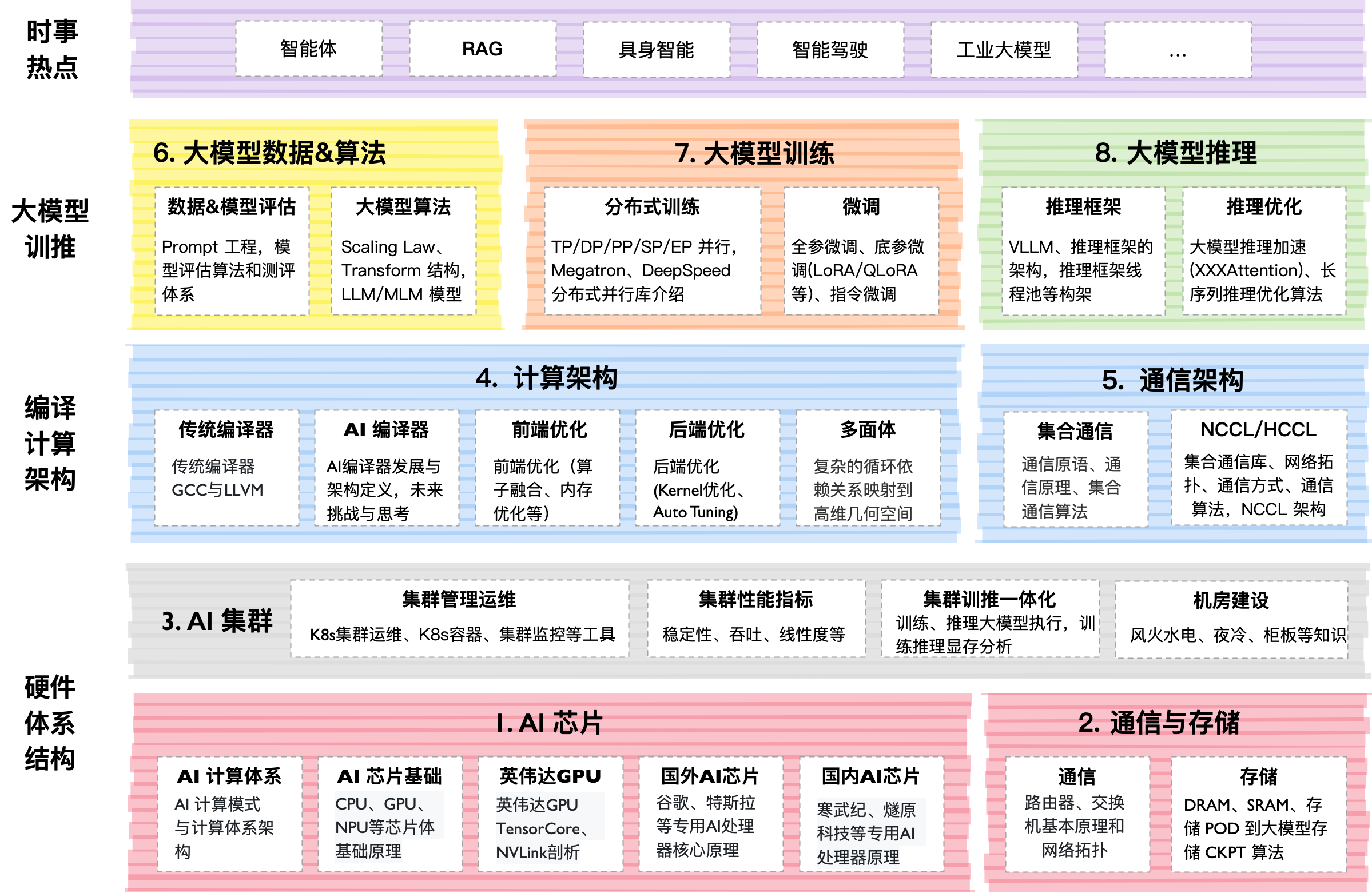
技術的内部構造
プロジェクトは「生きている本」形式で公開されています。メインのコンテンツは数字(00〜07)でディレクトリ分けされています。各ディレクトリには説明付きのMarkdownファイル、PDFスライド、Jupyterノートブックが入っています。
注目に値するもの:
- 実践:Flash Attentionをゼロから実装するコードがあります。
- 深さ:Scaling LawsのCoverage — より多くのデータとGPUを与えればモデルがどれほど賢くなるかを予測する数学的法則。
- 規模:高解像度グラフィックやダイアグラムの多さにより、リポジトリ全体で約10GBあります。著者はReleasesから必要な部分だけをダウンロードすることを推奨しています。
なぜこれを学ぶべきか
MLの世界は「単に訓練する」から複雑なエンジニアリングシステムへと急速に移行しています。今日需要があるのは、model.fit()の呼び出し方を知っている人ではなく、GPUをコンテナに渡す方法、K8sでリソース監視をセットアップする方法、勾配チェックポインティングでメモリ消費を最適化する方法を知っている人です。
AIInfraは、この排他的なシステムエンジニアクラブへの無料チケットです。たとえ独自のChatGPTを構築する予定がなくても、メモリアーキテクチャとネットワークプロトコルの知識は、どんな普通のデータサイエンティストよりも一歩も二歩も先を行くことができます。
どこから始めるか
飛び込むことを決めたら、一度にすべてを読もうとしないでください。推奨パス:
- セクション
04Trainで並列性の魔法を理解しましょう。 - セクション
06AlgoDataのノートブックをTransformerからダウンロードしてローカルで実行してみましょう。 - セクション
05Inferの推論に関するスライドを見ましょう — これはAIを扱うバックエンド開発者にとっての基礎です。
プロジェクトは常に更新されており、言語の混在により混沌としているように見えるかもしれませんが、今日利用可能なAIインフラに関する最も包括的な知識アグリゲーターです。学ぶ価値があるか?現在の流行が過ぎ去った後も業界に留まるつもりなら、答えは絶対的に「はい」です。
関連プロジェクト