Wie neuronale Netzwerk-Giganten unter der Haube funktionieren
Als ich zum ersten Mal versuchte zu verstehen, wie Modelle wie Llama oder DeepSeek auf Tausenden von GPUs trainiert werden, stieß ich an eine Wand. PyTorch-Tutorials erklären, wie man einen Katzen-Klassifikator trainiert, aber sie schweigen sich darüber aus, wie man zehntausend GPUs dazu bringt, ohne Verzögerungen miteinander zu kommunizieren. Das AIInfra-Projekt ist genau die Ressource, die Entwickler brauchen, wenn sie beschließen, einen Blick unter die Haube von Large Language Models (LLMs) zu werfen.
Was ist dieses Biest
AIInfra (AI Infrastructure) ist ein massives Bildungsrepository, das Schritt für Schritt aufschlüsselt, wie die Infrastruktur neuronaler Netzwerke funktioniert. Sein Autor, bekannt in der Community als ZOMI, hat alles zusammengebracht: vom physischen Design von Servern und Netzwerk-Switches bis hin zu verteilten Trainingsalgorithmen und Inferenzstrategien.
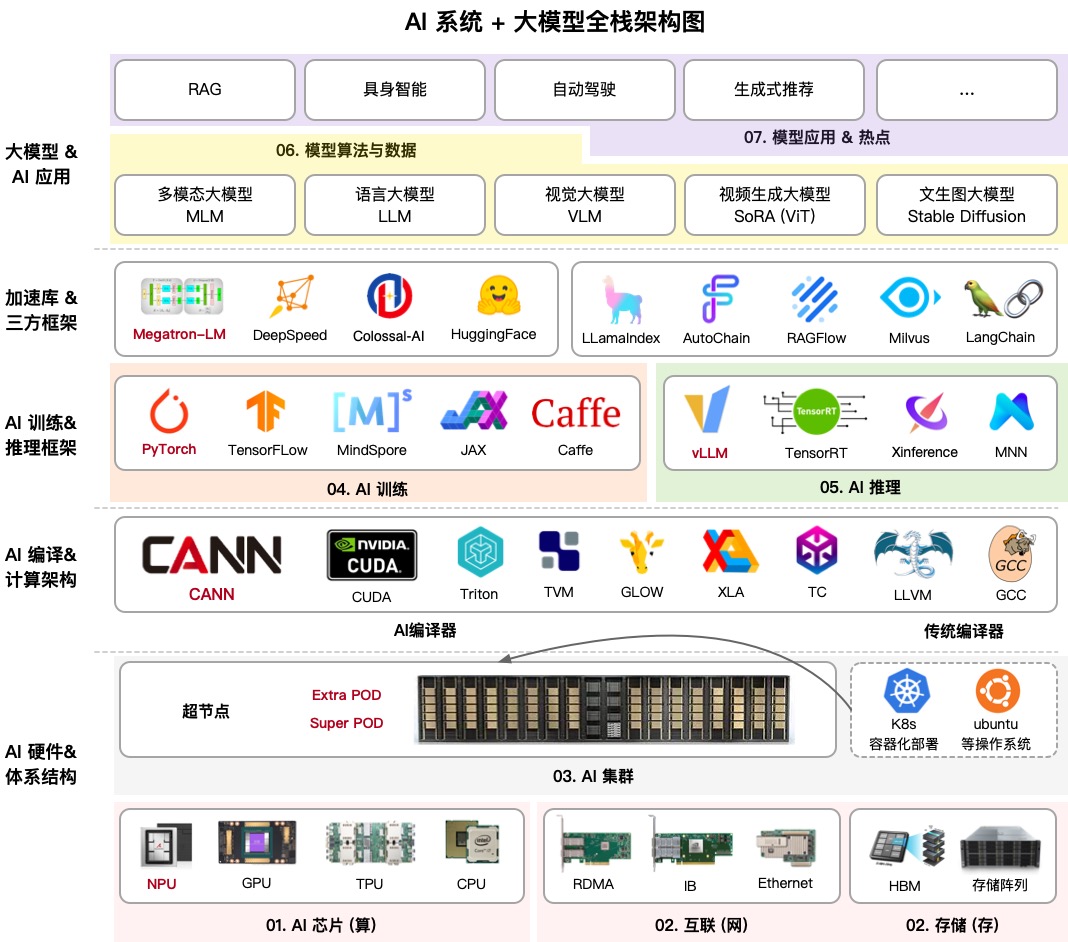
Wenn Sie dachten, es geht nur um das Schreiben von Python-Code, wird Sie dieses Projekt überraschen. Es behandelt das Kühlen von Server-Racks in Rechenzentren, InfiniBand-Netzwerktopologien und warum gewöhnliches Ethernet das Training moderner LLMs nicht bewältigen kann. Dies ist eine vollständige Wissenslandkarte für diejenigen, die sich als ML-Engineers oder Systemarchitekten im AI-Zeitalter bezeichnen möchten.
Für wen dieser Leitfaden gedacht ist
Das Projekt wird für diejenigen nützlich sein, die sich in den Grenzen der einfachen Nutzung von OpenAI- oder Anthropic-APIs eingeengt fühlen. Wenn Sie:
- verstehen müssen, warum Ihr Modell langsam trainiert, obwohl Sie leistungsstarke GPUs gekauft haben.
- herausfinden möchten, wie Daten-, Tensor- und Pipeline-Parallelität funktionieren.
- Ihren eigenen Kubernetes-Cluster für neuronale Netzwerk-Workloads einrichten müssen.
Interessanterweise bietet der Autor nicht nur Theorie, sondern enthält auch Jupyter-Notebooks und Folien. Einige Inhalte sind auf Chinesisch, aber der Code und englische Begriffe in Diagrammen sind intuitiv, und moderne Übersetzer bewältigen den Rest problemlos.
Fünf Stufen des Eintauchens in AIInfra
Das Repository ist in logische Module unterteilt. Ich habe diejenigen hervorgehoben, die für die Praxis am nützlichsten erschienen.
1. Hardware und Cluster
Hier erhalten Sie die Grundlagen: wie Serverknoten strukturiert sind, wie die Kühlung funktioniert und warum sich GPUs/NPUs unterschiedlich verhalten. Der Abschnitt über 10.000-Karten-Cluster ist besonders nützlich. In meiner Praxis muss ich selten in solchen Maßstäben arbeiten, aber zu verstehen, wie Ressourcen dort verteilt werden, hilft, auch kleinere Setups besser zu optimieren.
2. Kommunikation und Speicherung
Massive Modelle können nicht einfach über das Netzwerk gesendet werden. AIInfra erklärt ausführlich kollektive Kommunikationsbibliotheken wie NCCL (von NVIDIA) und HCCL (von Huawei). Wenn Sie jemals den Fehler NCCL TIMEOUT gesehen haben, wird Ihnen dieser Abschnitt helfen zu verstehen, genau wo im Netzwerk-Stack etwas schiefgelaufen ist.
3. Verteiltes Training
Dies ist das „Fleisch" des Projekts. Der Autor seziert PyTorch DDP (Distributed Data Parallel) und DeepSpeed bis auf die Knochen. Es gibt sogar praktische Beispiele:
# Пример из материалов: создание своего DDP с нуля
# Помогает понять, что под капотом у стандартных библиотек
import torch.distributed as dist
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# Дальше идет логика распределения градиентов
Hier erklärt er auch die ZeRO-Technologie (Zero Redundancy Optimizer), die das Training von Modellen ermöglicht, die nicht in den Speicher einer einzelnen GPU passen, indem Optimierer-Zustände aufgeteilt werden.
4. Modellarchitekturen: Transformer und MoE
Anstatt einfach „Attention verwenden" zu sagen, zeigt das Projekt, wie deren Variationen implementiert werden (MHA, GQA, MLA) und wie Sparse-Modelle (Mixture of Experts) strukturiert sind. Letzteres ist derzeit entscheidend wichtig, da nahezu alle Top-Open-Source-Modelle auf diesem Prinzip aufgebaut sind.
5. Inferenz und Optimierung
Das Training ist nur die halbe Miete. Sie brauchen auch, dass das Modell schnell antwortet. AIInfra behandelt KV-Caching, Quantisierung und Destillation. Dies sind genau die Tricks, mit denen Sie ein leistungsstarkes Modell auf Heimhardware oder günstigen Cloud-Instanzen ausführen können.
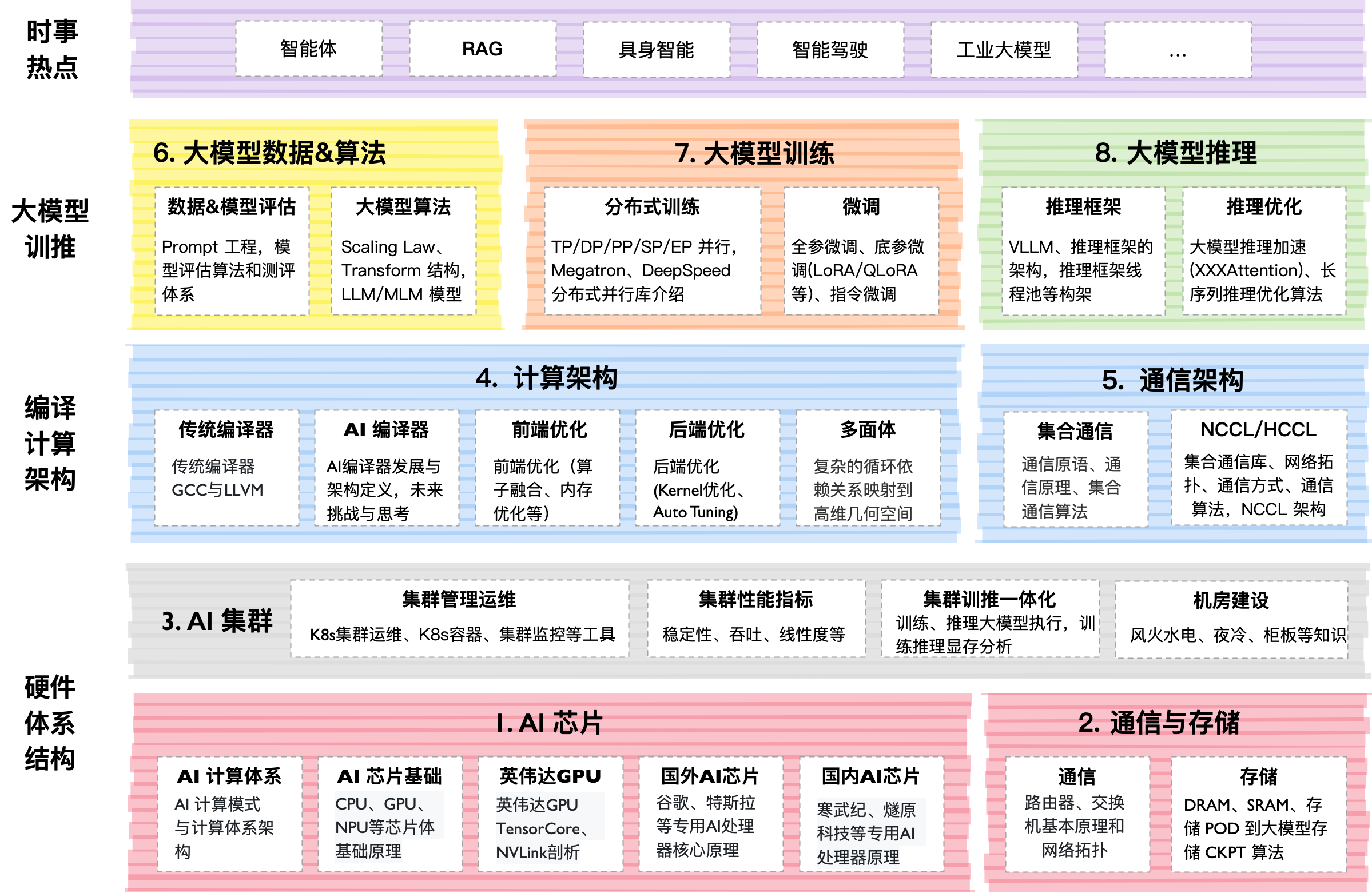
Technische Interna
Das Projekt lebt in einem Format eines „lebenden Buches". Die Hauptinhalte sind in Verzeichnissen nach Nummern organisiert (00–07). In jedem befinden sich Markdown-Dateien mit Erklärungen, PDF-Folien und Jupyter-Notebooks.
Was meine Aufmerksamkeit erregt hat:
- Praxis: Es gibt Code für die Implementierung von Flash Attention von Grund auf.
- Tiefe: Abdeckung von Scaling Laws – die mathematischen Gesetze, die vorhersagen, wie viel intelligenter ein Modell wird, wenn man ihm mehr Daten und GPUs gibt.
- Umfang: Das gesamte Repository wiegt etwa 10 GB aufgrund der Fülle an hochauflösenden Grafiken und Diagrammen. Der Autor empfiehlt sogar, nur die benötigten Teile über Releases herunterzuladen.
Warum Sie dies lernen sollten
Die ML-Welt bewegt sich schnell weg von „einfach trainieren" hin zu komplexen Ingenieurssystemen. Heute wird nicht jemand gesucht, der weiß, wie man model.fit() aufruft, sondern jemand, der versteht, wie man durch eine GPU zu einem Container gelangt, die Ressourcenüberwachung in K8s einrichtet und den Speicherverbrauch durch Gradienten-Checkpointing optimiert.
AIInfra ist eine kostenlose Eintrittskarte in diesen exklusiven Club von Systemingenieuren. Selbst wenn Sie nicht vorhaben, Ihren eigenen ChatGPT zu bauen, wird das Wissen über Speicherarchitektur und Netzwerkprotokolle Sie weit über jeden gewöhnlichen Data Scientist erheben.
Wo Sie anfangen sollten
Wenn Sie sich entschließen einzutauchen, versuchen Sie nicht, alles auf einmal zu lesen. Ich empfehle diesen Weg:
- Werfen Sie einen Blick auf Abschnitt
04Train, um die Magie der Parallelität zu verstehen. - Laden Sie das Notebook von
Transformerin Abschnitt06AlgoDataherunter und versuchen Sie, es lokal auszuführen. - Schauen Sie sich die Folien zur Inferenz in
05Inferan – das ist die Grundlage für jeden Backend-Entwickler, der mit AI arbeitet.
Das Projekt wird ständig aktualisiert, und obwohl es aufgrund der Sprachmischung chaotisch erscheinen mag, ist es der umfassendste Wissensaggregator zur AI-Infrastruktur, der heute verfügbar ist. Lohnt es sich zu studieren? Absolut, wenn Sie planen, länger in der Branche zu bleiben als der aktuelle Hype anhält.
Ähnliche Projekte