Come Funzionano i Giganti delle Reti Neurali Sotto il Cofano
Quando ho cercato per la prima volta di capire come modelli come Llama o DeepSeek vengono addestrati su migliaia di GPU, ho incontrato un muro. I tutorial di PyTorch spiegano come addestrare un classificatore di gatti, ma non dicono nulla su come far comunicare diecimila GPU tra loro senza ritardi. Il progetto AIInfra è esattamente la risorsa di cui gli sviluppatori hanno bisogno quando decidono di guardare sotto il cofano dei large language models (LLM).
Cos'è Questa Bestia
AIInfra (AI Infrastructure) è un enorme repository educativo che scompone passo dopo passo come funziona l'infrastruttura delle reti neurali. Il suo autore, noto nella community come ZOMI, ha raccolto tutto: dal design fisico dei server e degli switch di rete agli algoritmi di training distribuito e alle strategie di inferenza.
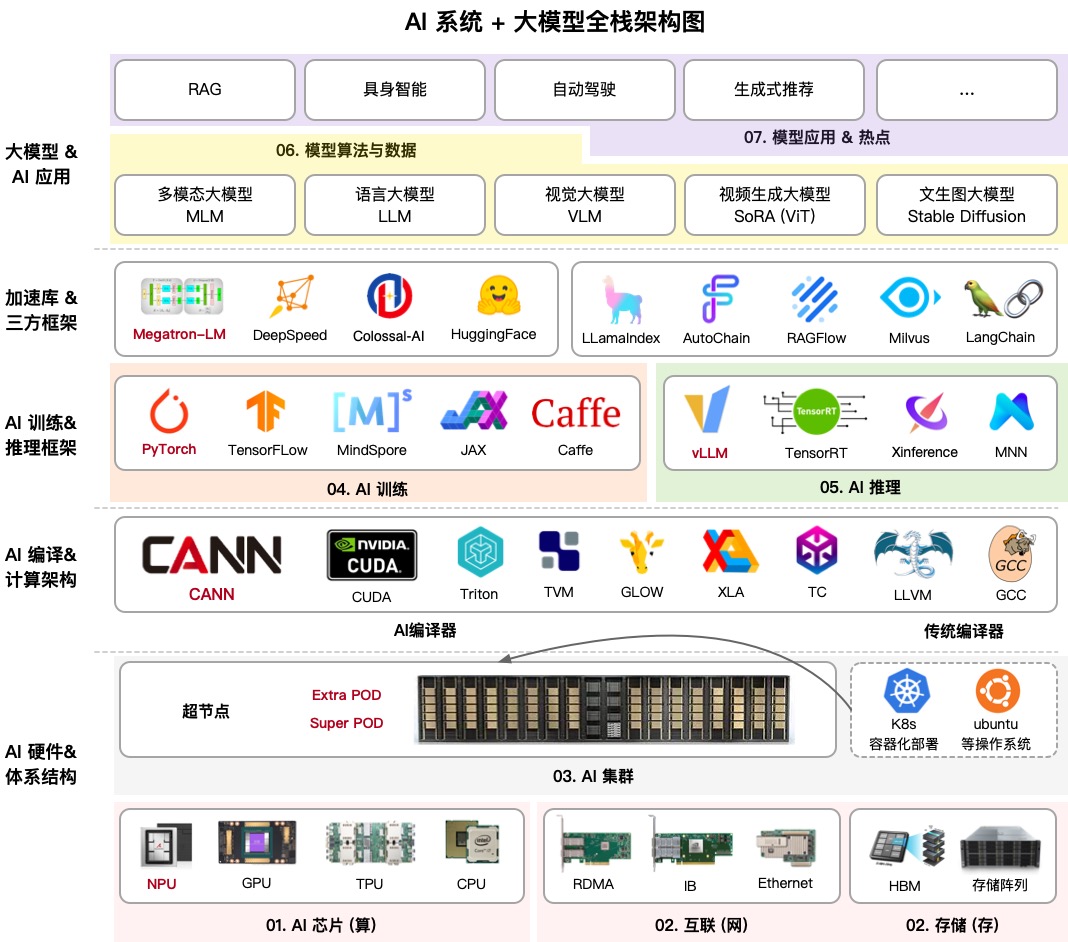
Se pensavi che fosse tutto scrivere codice Python, questo progetto ti sorprenderà. Copre il raffreddamento dei rack server nei data center, le topologie di rete InfiniBand, e perché l'Ethernet tradizionale non può gestire l'addestramento degli LLM moderni. Questa è una mappa completa delle conoscenze per chi vuole chiamarsi ingegnere ML o architetto di sistemi nell'era dell'AI.
Per Chi È Scritta Questa Guida
Il progetto sarà utile per chi si sente stretto nei limiti del semplice utilizzo delle API di OpenAI o Anthropic. Se hai bisogno di:
- Capire perché il tuo modello si addestra lentamente anche se hai acquistato GPU potenti.
- Scoprire come funzionano la parallelism dei dati, dei tensori e delle pipeline.
- Configurare il tuo cluster Kubernetes per carichi di lavoro di reti neurali.
Interessante notare che l'autore non si limita a fornire teoria ma include anche Jupyter notebook e slide. Alcuni contenuti sono in cinese, ma il codice e i termini inglesi nei diagrammi sono intuitivi, e i traduttori moderni gestiscono facilmente il resto.
Cinque Livelli di Approfondimento in AIInfra
Il repository è suddiviso in moduli logici. Ho evidenziato quelli che mi sono sembrati più utili per la pratica.
1. Hardware e Cluster
Qui trovi le basi: come sono strutturati i nodi server, come funziona il raffreddamento, e perché GPU/NPU si comportano diversamente. La sezione sui cluster da 10.000 schede è particolarmente utile. Nella mia pratica, raramente ho bisogno di lavorare a queste scale, ma capire come le risorse vengono distribuite aiuta a ottimizzare meglio anche configurazioni più piccole.
2. Comunicazioni e Storage
I modelli massivi non possono semplicemente essere inviati sulla rete. AIInfra spiega approfonditamente le librerie di comunicazione collettiva come NCCL (di NVIDIA) e HCCL (di Huawei). Se hai mai visto l'errore NCCL TIMEOUT, questa sezione ti aiuterà a capire esattamente dove è andato storto nello stack di rete.
3. Training Distribuito
Questa è la "carne" del progetto. L'autore seziona PyTorch DDP (Distributed Data Parallel) e DeepSpeed fino all'osso. Ci sono persino esempi pratici:
# Пример из материалов: создание своего DDP с нуля
# Помогает понять, что под капотом у стандартных библиотек
import torch.distributed as dist
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# Дальше идет логика распределения градиентов
Qui spiega anche la tecnologia ZeRO (Zero Redundancy Optimizer), che permette di addestrare modelli che non entrano nella memoria di una singola GPU dividendo gli stati dell'optimizer.
4. Architetture dei Modelli: Transformer e MoE
Invece di dire semplicemente "usa Attention", il progetto mostra come implementare le sue varianti (MHA, GQA, MLA) e come sono strutturati i modelli sparsi (Mixture of Experts). Questi ultimi sono criticamente importanti ora, poiché quasi tutti i migliori modelli open source sono costruiti su questo principio.
5. Inferenza e Ottimizzazione
Il training è solo metà della battaglia. Devi anche far sì che il modello risponda rapidamente. AIInfra copre KV-caching, quantizzazione e distillazione. Questi sono proprio i trucchi che ti permettono di eseguire un modello potente su hardware domestico o istanze cloud economiche.
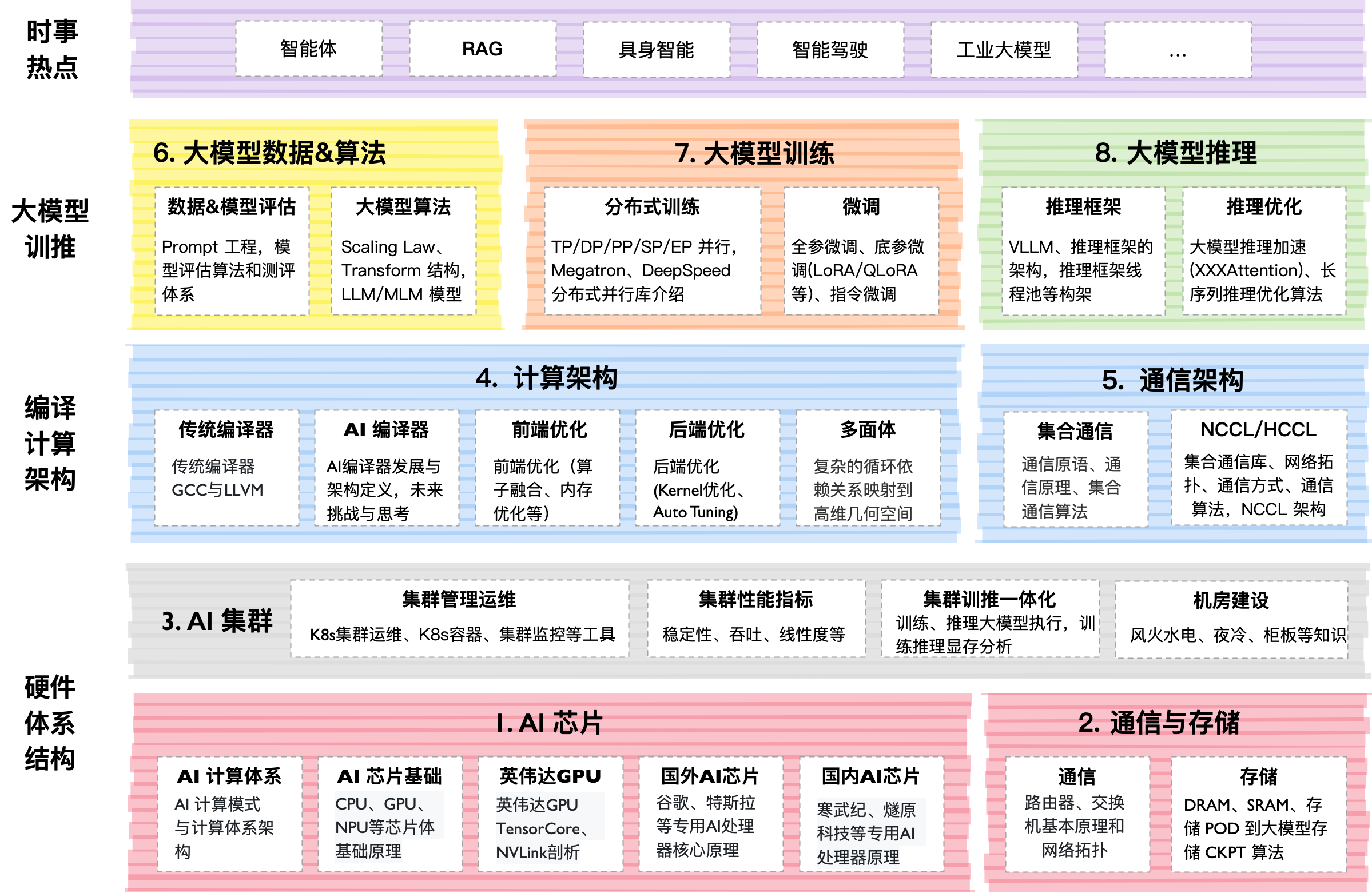
Interni Tecnici
Il progetto vive in un formato "libro vivente". I contenuti principali sono organizzati in directory per numeri (00–07). All'interno di ciascuna ci sono file Markdown con spiegazioni, slide PDF e Jupyter notebook.
Cosa ha attirato la mia attenzione:
- Pratica: C'è codice per implementare Flash Attention da zero.
- Profondità: Copertura delle Scaling Laws — le leggi matematiche che predicono quanto più intelligente diventerà un modello se gli dai più dati e GPU.
- Dimensione: L'intero repository pesa circa 10 GB per l'abbondanza di grafica e diagrammi ad alta risoluzione. L'autore consiglia persino di scaricare solo le parti necessarie tramite Releases.
Perché Dovresti Imparare Questo
Il mondo ML si sta muovendo rapidamente via da "semplicemente addestrare" verso sistemi di ingegneria complessi. Oggi, ciò che è richiesto non è qualcuno che sappia come chiamare model.fit(), ma qualcuno che capisca come passare attraverso una GPU a un container, configurare il monitoraggio delle risorse in K8s, e ottimizzare il consumo di memoria attraverso il gradient checkpointing.
AIInfra è un biglietto gratuito per questo club esclusivo di ingegneri di sistemi. Anche se non prevedi di costruire il tuo ChatGPT, la conoscenza dell'architettura della memoria e dei protocolli di rete ti metterà un gradino sopra qualsiasi data scientist ordinario.
Da Dove Iniziare
Se decidi di immergerti, non cercare di leggere tutto in una volta. Ti consiglio questo percorso:
- Dai un'occhiata alla sezione
04Trainper capire la magia del parallelismo. - Scarica il notebook da
Transformernella sezione06AlgoDatae prova a eseguirlo localmente. - Guarda le slide sull'inferenza in
05Infer— questa è la base per qualsiasi sviluppatore backend che lavora con l'AI.
Il progetto viene costantemente aggiornato, e sebbene possa sembrare caotico per la mescolanza di lingue, è l'aggregatore di conoscenze più completo sull'infrastruttura AI disponibile oggi. Vale la pena studiarlo? Assolutamente sì, se prevedi di restare nel settore più a lungo dell'hype attuale.
Progetti correlati